버츄얼유튜버
Attention과 Transformer
두원공대88학번뚜뚜
2022. 8. 31. 17:29
https://velog.io/@idj7183/Attention-TransformerSelf-Attention
Attention, Transformer(Self-Attention)
Attention, Transformer(Self-Attention)
velog.io
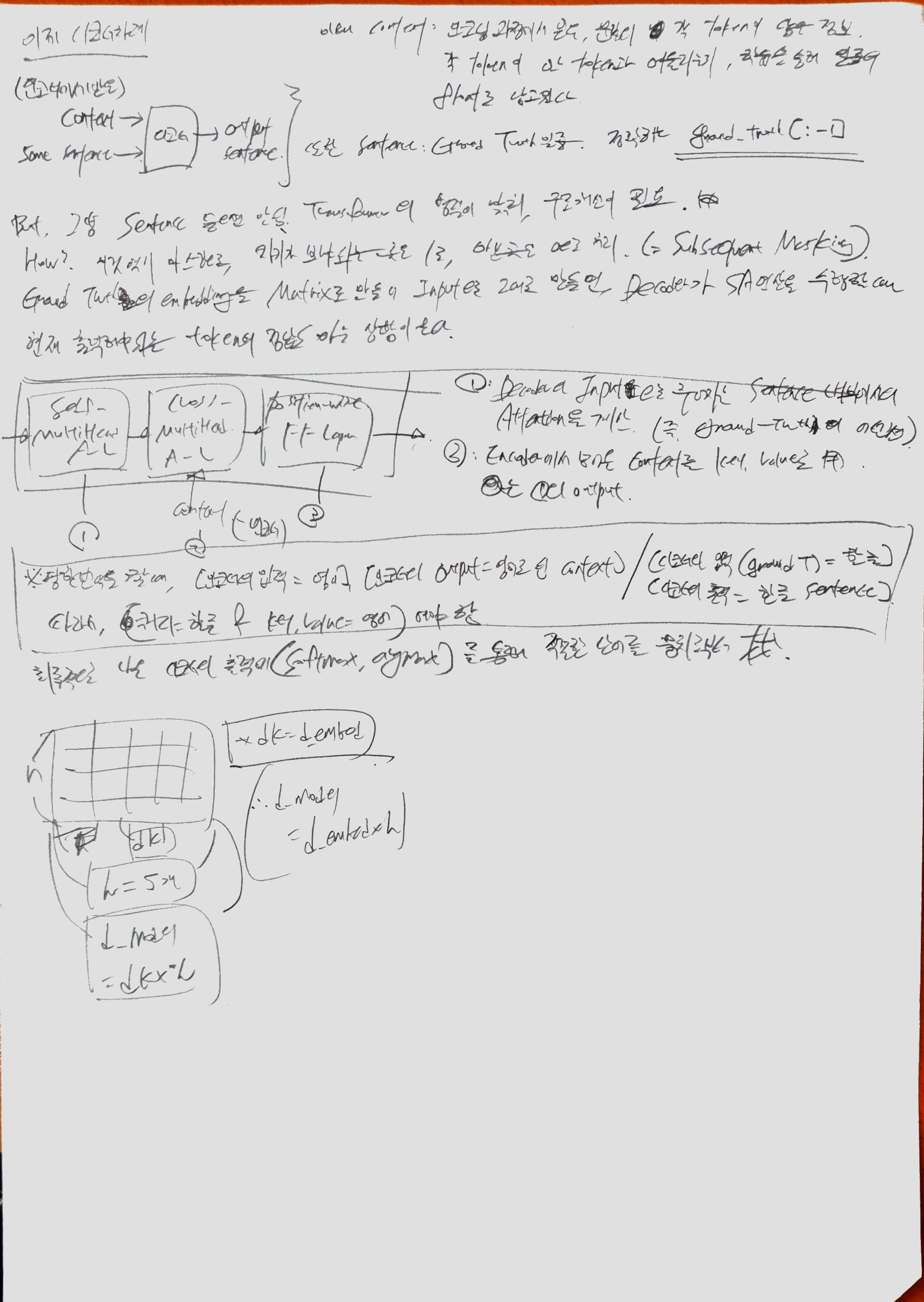
Attention : Decoder에서 출력 단어를 예측하는 시점마다 Encoder에서의 전체 입력 문장을 다시 한 번 참고4
기본 계산(메커니즘)

Generalized Dot Product : Dot Product 사이에 특정행렬(여기선 Wa)를 추가시킴. 이 Wa는 학습 가능한 행렬.
Dot Product와 General Product의 연산 결과는 Scalar이기에, Wa의 형태는
(Hidden State Vector Dimension) X (Hidden State Vector Dimension) 과 같다.
Concat : Decoder Hidden State Vector와 Encoder의 Hidden State Vector(Q)를 Concat시키고, 이를 Wa(가중치행렬)과 곱해서 중간 Hidden Layer을 만듦.