
Vision Transformer(22.03.03 재포스팅)
쉽게 이해하는 ViT(Vision Transformer) 논문 리뷰 | An Image is Worth 16x16 Words: Transformers for Image Recognition at
ViT(Vision Transformer) 논문 리뷰를 해보겠습니다. Transformer는 NLP 테스크에서 Bert, GPT-3 등 기반 알고리즘으로 유명하죠. 이런 Transformer 알고리즘을 Vision 분야에서 사용합니다. 시작하기 앞서서 Tra..
hipgyung.tistory.com
An Image is Worth 16x16 Words: Transformers for Image Recognition (Paper Explained)
whoisnnamdi.com
Vision Transformer (AN IMAGE IS WORTH 16X16 WORDS, TRANSFORMERS FOR IMAGE RECOGNITION AT SCALE)
gaussian37's blog
gaussian37.github.io
논문 원본 - 2010.11929.pdf (arxiv.org)
이미지에 대한 SA의 적용은, 단순한 차원에서는 각 픽셀이 다른 모든 픽셀에 주의를 기울여야 한다. 그러나 픽셀 수를 고려하면, 이는 현실적으로 어렵다. 따라서 이미지 처리의 맥락에서 트랜스포머를 적용하기 위해 몇 가지 근사치가 시도되었다.
1) Parmar et al.(2018): 전체 부위(global) 대신 각 쿼리 픽셀에 대해 로컬 이웃(local neighborhoods)에서만 자기 주의를 적용했다.
2) 희소(sparse) 트랜스포머(Child et al., 2019) : 이미지에 적용하기 위해, 전역SA에 확장 가능한 근사치(Scalable Approximations)를 사용한다.
3) 주의를 확장하는 다른 방법 : 다양한 크기의 블록에 적용하는 것이다(Weissenborn et al., 2019). 극단적인 경우에는 개별 축을 따라서만 적용한다(Ho). 이러한 특수 Attention 아키텍처의 대부분은 복잡한 엔지니어링이 필요하다.
4) 가장 요주의 Cordonnier et al.의 모델 : 2X2 사이즈의 이미지패치를 인풋이미지로부터 추출해, 위(top)에서 완전 Self-Attentinon을 적용하는 것.ViT와 매우 유사하며, 저/중간 해상도에 적합. 여기에 cnn을 결합하여 더 많은 활용도에 쓸 수 있다고도 한다.
최근 모델 - 이미지 해상도와 색 공간을 줄이고, 이미지 픽셀에 트랜스포머를 적용하는 이미지GPT(iGPT)도 존재.
4번 모델의 소개:
이미지패치에 위치임베딩(position embedding)의 시퀀스를 추가해 Transformer에 입력. 이 패치는 NLP의 토큰처럼 활용된다. 모델에서는 이미지분류 태스크에 대해, 지도학습 방식으로 학습. 분류 과제를 수행하기 위해, 추가적으로 학습되는 Classification token을 만들어 시퀀스에 더함.

인풋 : 2차원 이미지를 다루기 위해, 논문에선 이미지를 Flatten된 2차원패치의 시퀀스로 변환. 즉 (H, W, C)의 이미지를 (N, P^2 C)로 변환하는데, 이 때 각각
- N = HW/P^2 =패치의 개수
- (P, P) = 이미지패치의 크기
- (H, W, C) = Height, Width, Channel
로, (패치 수 * 패치 사이즈)로 구조가 변경된 것을 볼 수 있다. 하나의 row에 하나의 패치가 들어간 것을 볼 수 있다.
이전 트랜스포머에서 단어를 d_embed(또는 dk) 사이즈로 임베딩시키고 Positional Encoding을 추가한 것 처럼, 비전트랜스포머는 모든 레이어에서 고정된 벡터크기 D를 사용하기에, 이미지 패치는 펼친다음 D차원 벡터로 linear projection 시킨다. 다음으로, 임베딩된 패치의 시퀀스에 z0 = x_class 임베딩을 추가로 붙여넣음. 이 임베딩은, 위치임베딩임.
순서는 아래와 같다.
- ① Transformer와 동일한 구조의 입력 데이터를 만들기 위해서 이미지를 패치 단위로 쪼개고 각 패치를 왼쪽 상단에서 오른쪽 하단의 순서로 나열하여 시퀀스 데이터 처럼 만든다.
- ② Transformer에서 Embedding된 데이터는 벡터값을 가지므로 각 패치는 flatten 하여 벡터로 변환해 준다.
- ③ 각 벡터에 Linear 연산을 거쳐서 Embedding 작업을 한다.
- ④ Embedding 작업의 결과에 클래스를 예측하는 클래스 토큰(아마 패치가 합쳐진, 전체 이미지에 대한 임베딩값)을 하나 추가한다(Extra learnable [CLASS] embedding).
- ⑤ 클래스 토큰이 추가된 입력값에 Positional Embedding(번호 옆의 분홍색)을 더해주면 Vision Transformer의 입력이 완성이 된다. 이미지에서도 각 패치의 위치가 중요하기 때문에 Positional Embedding을 적용해 주게 된다.
(1) - 입력 수식
Xclass : classification token. 따라서 각각의 XNpE는 각각의 patch로 나눠진 이미지 시퀀스가 된다.
E : 임베딩 매트릭스. 따라서, Xclass(n번째 패치인 XnP)와 E를 곱함으로써 D차원의 벡터로 임베딩시킨다.
Epos : 시퀀스의 순서를 나타내는 Positional Encoding이 추가됨.
잘 보면 E는 기존의 token에 R^(P^2 * C)에 D제곱 되어있음을 볼 수 있다. Epos 역시 (패치의 개수+1) 차원에서 표현되며, 이를 통해 기존의 (P^2 * C)이던 Xclass에 (P^2 * C)xD를 곱함으로써 최종적으로 (N*D)차원으로 임베딩을 시키는것.
물론 배치사이즈를 고려하면 (B,N,D)이긴 하지만 일단 넘어간다.
앞서서 Epos에 1을 더해주었는데, 이는 Positional Encoding을 추가했기 때문이다. 위의 순서의 5번을 보면 알 수 있다.
(2) - Transformer에 해당하는 수식. MSA = Multiheaded Self Attention
트랜스포머 특징처럼, 인코더는 L번 반복되며, 입력과 출력의 사이즈는 같아야 한다.
기존 트랜스포머완 반대로, Layer Norm을 먼저 진행한 다음 MultiHead Attention을 적용한다.
입력값 z0[수식1]에서 시작해, L번 반복한 zl[수식 3]이 최종 인코더의 출력이 된다.
이전 입력값에 Layer Normalization(=LN)을 한 다음, Multi-Head Attention을 적용. 해당 값을 Skip Connection.
이 LN은, D차원에 대해 각 feature에 대한 정규화를 진행한다.
간략한 LN의 설명
기존 배치정규화는, 하나의 배치에 대해 정규화를 진행했다. 좌측 맨 위의 1,3,6이 하나의 배치임.
근데 LN은 이와 달리, 여러 배치의 같은 위치에 대해 정규화를 진행. 즉, 우하단의 Same for all feature dimensions를 보듯, D차원으로 만들어진 것들의 동일한 위치(=각 배치의 같은 feature의 값)을 정규화.

Transformer Encoder가 L번 반복할 때, i번째에서의 입력이 zi라 하면,

해당 식을 LN한다고 가정한다. D차원 방향으로 각 feature에 대해 정규화를 진행.
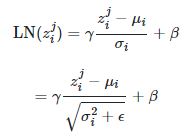
그럼 왼쪽의 식이 되며, r와 b는 학습 가능한 파라미터.
하단의 분모 변경은 분산이 0에 가까워졌을 때, 처리하기 위한 트릭이라 한다.
보면 알 수 있듯,
(각 feature - 평균) / 분산의 식을 따르고 있다.
이렇게 해서 LN을 진행하면 인코딩의 출력값에 대한 정규화가 완료됨.
이제 Multi-Head Attention을 적용해본다. 기존 Transformer처럼 Query, Key, Value를 가짐.

위의 과정을 통해 획득한 z_(l-1)에, 기존에 학습시킨 wq, wk, wv를 곱하여 qkv를 얻는다. 맨 아래는 q, k, v를 한번에 연산하기 위한 식이다.

이후에 식1 & 식2를 통해 각 head에서의 SA(Self-Attention) 결과를 뽑고, 식 3을 통해 각 head의 SA 결과를 묶은 다음, Linear 연산을 통해 최종적으로 Multi-head Attention의 결과를 얻는다.
식 3에서 SA의 결과를 묶은 결과는 (N, Dh, k)이며, Umsa는 (k, Dh, D)이므로, 연산의 결과는 (N, D)가 된다. 이 과정을 통해, Transformer Encoder의 입력과 같은 shape를 갖도록 조절이 가능.
실제 Multi-Head Attention을 구현할 때, 각 head의 에 대한 연산을 따로 하지 않고 한번에 처리할 수 있다 한다.

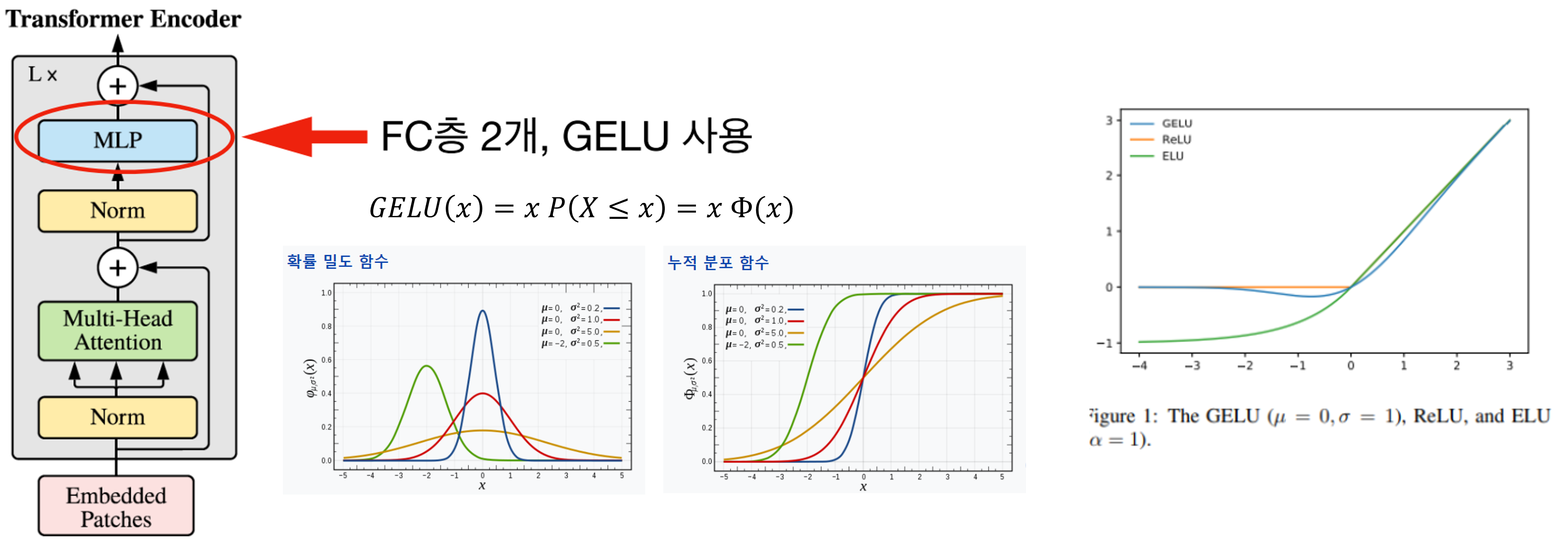
(3) - MLP(Multi Layer Perceptron, 다층 퍼셉트론) Head에 해당하는 수식.
이후 MLP를 진행한 다음, GELU를 실행.
GELU : 입력값과 입력값의 누적분포의 곱을 사용한 형태.
입력값 x가 다른 입력에 비해 얼마나 큰지에 대한 비율로 값이 조정되어, 확률적 해석이 가능하다...고 한다.
(4) - 마무리 수식
마무리로 L번 반복한 Transformer Encoder의 마지막 출력에서 '클래스토큰'만 분류문제에 쓰게 되며, 마지막에 추가적 MLP를 통해 클래스를 분류한다.


해석

- 가장 좌측의 RGB Embedding Filter, 즉 Transformer Encoder에 입력되기 전 Embedding을 할때 사용한 filter을 시각화해보면, ViT는 마치 CNN처럼 학습이 된다.
- 중간의 Positional Embedding는 각 패치마다 대응되는 Embedding 벡터가 존재한다. 이 모든 패치 p(i, pj)에 대해 Cosine Similarity를 구할 시의 row, col에 해당하는 부분의 패치가 Similarity가 높은 것을 통해, Position이 의미가 있도록, 즉 Positional Embedding이 데이터의 위치를 잘 위미하도록 학습이 잘 되었다는 것을 알 수 있다.
- 가장 오른쪽의 그래프는 attention이 관심을 두는 위치의 편차를 나타낸다. low level layer에서는 가까운 곳에서부터 먼 곳까지 모두 살펴보는 반면 high level layer로 전체적으로 본다는 것을 의미한다. y축의 distance의 의미는 어떤 query 위치를 기준으로 의미있는 영역까지의 평균 거리를 나타낸다. 이 거리가 짧을수록 가까운 영역에 대하여 attention을 한다는 것이고 이 거리가 길수록 먼 영역에 대하여 attention을 한다는 것을 의미한다.
- CNN 또한 convolution 연산의 특성상 layer가 깊어질수록 점점 더 큰 영역을 보게되는데 Vision Transformer 또한 그러한 성질을 가지는 것을 확인할 수 있었다.... 고 한다.
ViT의 위치 임베딩에 대한 명확한 근거가 없다는 것이 맞습니다. 그러나 위치 임베딩은 이미지 분류 또는 객체 감지와 같은 주요 작업에서 제공하는 감독 신호를 통해 간접적으로 학습됩니다.
훈련 중에 모델은 해당 레이블과 함께 입력 이미지를 수신합니다. 모델은 입력 이미지를 사용하여 형상 표현을 계산한 다음 분류 또는 탐지 헤드에 입력되어 레이블을 예측합니다. 위치 임베딩을 포함한 전체 모형의 모수는 예측 레이블과 실제 레이블 간의 차이를 최소화하도록 최적화됩니다.
위치 임베딩은 입력 이미지에 대한 공간 정보를 인코딩하는 데 사용되기 때문에 분류 또는 탐지 헤드가 사용하는 형상 표현에 간접적으로 기여합니다. 훈련 중 위치 임베딩의 값을 조정함으로써 모델은 형상 표현에서 중요한 공간 정보를 인코딩하는 방법을 배울 수 있으며, 이는 주요 작업에 대한 모델의 성능을 향상시키는 데 도움이 될 수 있습니다.
역전파 알고리듬은 훈련 중에 위치 임베딩을 포함하여 모델의 매개 변수를 업데이트하는 데 사용됩니다. 역전파 중에 매개 변수에 대한 손실 그레이디언트가 계산되어 손실을 최소화하는 방향으로 매개 변수를 업데이트하는 데 사용됩니다. 즉, 위치 임베딩은 분류 또는 탐지 헤드에서 사용하는 형상 표현을 통해 손실에 대한 기여도를 기반으로 업데이트됩니다.
요약하면, 위치 임베딩에 대한 명시적인 지상 진실은 없지만, 주요 작업에서 제공하는 감독 신호를 통해 간접적으로 학습됩니다. 훈련 중 위치 임베딩의 값을 조정함으로써 모델은 형상 표현에서 중요한 공간 정보를 인코딩하는 방법을 배울 수 있으며, 이는 주요 작업에 대한 모델의 성능을 향상시키는 데 도움이 될 수 있습니다. 역전파 알고리듬은 형상 표현을 통한 손실에 대한 기여를 기반으로 위치 임베딩을 업데이트하는 데 사용됩니다.
---
물론이죠! 여러분이 사과, 바나나, 그리고 오렌지와 같은 다른 과일들을 인식하도록 컴퓨터를 가르치고 싶다고 가정해 봅시다. 당신은 이 과일들의 많은 사진들을 컴퓨터에 보여주고 각각의 사진에 어떤 과일이 있는지 말해줍니다.
컴퓨터는 사진을 보고 사진 속의 것들이 과일을 인식하는데 중요한 것들이 무엇인지 알아내려고 노력합니다. 한 가지 중요한 것은 과일의 모양과 색깔입니다. 하지만 또 다른 중요한 것은 사진 속의 과일이 어디에 위치하고 있는지입니다. 예를 들어 사진의 왼쪽 위에 사과가 있으면 오른쪽 아래에 사과가 있는 것과 다릅니다.
컴퓨터가 그림에서 과일이 어디에 있는지 알 수 있도록 돕기 위해, 우리는 위치 임베딩이라고 불리는 것을 사용합니다. 이것은 그림에서 과일이 어디에 있는지 컴퓨터에 알려주는 숫자의 벡터입니다.
우리는 컴퓨터에 위치 임베딩이 무엇이어야 하는지 정확하게 말하지 않습니다. 대신, 우리는 컴퓨터가 사진의 과일을 얼마나 잘 인식할 수 있는지에 따라 내장된 위치에서 숫자를 조정하도록 합니다. 이를 역전파라고 합니다.
컴퓨터가 그림을 보고 과일을 인식하려고 하면, 그것의 추측과 정답을 비교합니다. 만약 답이 틀리면, 컴퓨터는 다음 번에 더 잘하려고 하기 위해 임베딩 위치의 숫자를 조정합니다. 시간이 지남에 따라 컴퓨터는 점점 더 많은 사진을 볼수록 과일을 인식하고 사진에서 과일이 어디에 있는지 파악하는 데 더 능숙해집니다.
그래서 그 위치 임베딩은 작은 도우미와 같습니다. 컴퓨터는 사진 속 과일이 어디에 있는지 기억하기 위해 사용합니다. 우리는 컴퓨터가 사진의 과일을 얼마나 잘 인식할 수 있는지에 따라 내장된 위치에서 숫자를 조정할 수 있도록 합니다. 이것은 역전파라고 불리는데, 이것은 우리가 각각의 사진에서 과일이 정확히 어디에 있는지 말할 필요 없이 컴퓨터가 과일이 어디에 있는지 알 수 있게 해줍니다.