[ConvLSTM] LSTM, RNN 확장판
An introduction to ConvLSTM
Nowadays it is quite common to find data in the form of a sequence of images. The most typical example is video at social networks such as…
medium.com
위의 거 걍 번역한거임
RNN 예전에 정리한 건 여기
https://jwgdkmj.tistory.com/315
ConvLSTM Theory
연속적인 기간 동안 수집된 데이터는 시계열로 표시됩니다. 이러한 경우, 흥미로운 접근 방식은 순환 신경망 아키텍처인 LSTM(Long Short Term Memory)을 기반으로 하는 모델을 사용하는 것입니다. 이러한 종류의 아키텍처에서 모델은 이전의 숨겨진 상태를 시퀀스의 다음 단계로 전달합니다. 따라서 네트워크가 이전에 본 이전 데이터에 대한 정보를 보유하고 이를 사용하여 의사 결정을 내립니다. 즉, 데이터 순서가 매우 중요합니다.
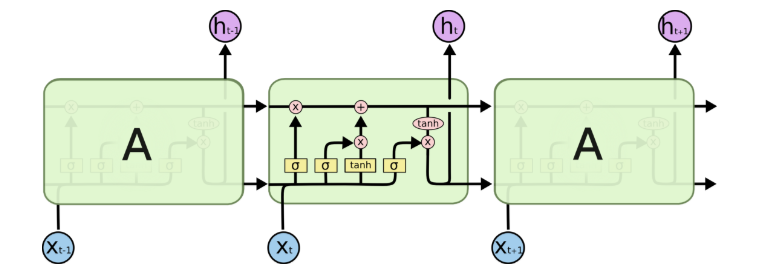
이미지로 작업할 때 가장 좋은 방법은 CNN(Convolutional Neural Network) 아키텍처입니다. 이미지는 여러 필터가 중요한 특징을 추출하는 컨볼루션 레이어를 통과합니다. 일부 컨볼루션 레이어를 순차적으로 통과하면 출력이 완전히 연결된 Dense 네트워크에 연결됩니다.

우리의 경우, 순차적 이미지의 한 가지 접근 방식은 ConvLSTM 레이어를 사용하는 것입니다. LSTM과 마찬가지로 반복 계층이지만 내부 행렬 곱셈은 컨볼루션 연산과 교환됩니다. 결과적으로 ConvLSTM 셀을 통해 흐르는 데이터는 기능이 있는 1D 벡터가 아닌 입력 차원(우리의 경우 3D)을 유지합니다.
ConvLSTM의 다른 접근 방식은 합성곱-LSTM 모델로, 이미지가 합성곱 레이어를 통과하고 결과는 얻은 특징을 가진 1D 어레이로 평평하게 설정됩니다. 이 프로세스를 시간 세트의 모든 영상에 반복하면 시간이 지남에 따라 일련의 형상이 생성되며, 이것이 LSTM 레이어 입력입니다.

케라스의 ConvLSTM 계층
이제부터 데이터 형식이 "channels_first"로 정의됩니다. 그러면 형식(Channels, Rows, Cols)을 가진 영상이 생성됩니다. 컬러풀한 RGB 3채널 300x300 픽셀 사진이 있습니다. 만약 그것이 컨볼루션 레이어의 케라스 기본값인 "channels_last"라면, 형식은 (행, 콜, 채널)이 될 것입니다.
ConvLSTM 계층 입력
LSTM 셀 Input은 시간 경과에 따른 데이터 세트, 즉 형상 (samples, time_steps, features)이 있는 3D 텐서입니다.
컨볼루션 레이어 입력은 형상(샘플, 채널, 행, 콜)이 있는 4D 텐서 이미지 세트입니다.
ConvLSTM의 Input은 시간이 지나며 연속되는 이미지세트의 (samples, time_steps, channels, rows, cols)을 가진 5D 텐서입니다.
ConvLSTM 계층 출력
LSTM 셀 출력은 return_sequences 속성에 따라 달라집니다. True를 설정하면 출력은 시간 경과에 따른 시퀀스(각 입력에 대해 출력 1개)가 됩니다. 이 경우 출력은 형상(samples, time_steps, features)이 있는 3D 텐서입니다. return_sequences가 False(기본값)로 설정된 경우 출력은 시퀀스의 마지막 값, 즉 형상 (samples, features)이 있는 2D 텐서가 됩니다.
컨볼루션 레이어 출력은 형상(samples, filters, rows, cols)이 있는 4D 텐서 이미지 세트입니다.
ConvLSTM 레이어 출력은 Convolution과 LSTM 출력의 조합입니다. LSTM과 마찬가지로, return_step = True이면 모양(samples, time_steps, filters, rows, cols)을 가진 5D 텐서로 시퀀스를 반환합니다. 반면에, return_tensor = False이면, 시퀀스의 마지막 값만 모양(samples, filters, rows, cols)을 가진 4D 텐서로 반환합니다.
기타 매개 변수
다른 ConvLSTM 속성은 Convolution 및 LSTM 계층에서 파생됩니다.
Convolution 계층에서 가장 중요한 요소는 다음과 같습니다:
1) 필터: 컨볼루션의 출력 필터 수입니다.
2) kernel_size: 컨볼루션 창의 높이와 너비를 지정합니다.
3) 패딩: "유효" 또는 "동일" 중 하나입니다.
4) data_format: 채널이 먼저("channels_first") 또는 마지막("channels_last")인 경우 영상 형식.
5) 활성화: 활성화 기능. 기본값은 선형 함수 a(x) = x입니다.
LSTM 계층에서 가장 중요한 것은 다음과 같습니다:
1) recurrent_activation: 반복 단계에 사용할 활성화 기능. 기본값은 hard sigmoid(hard_sigmoid)입니다.
2) return_timeout: 출력 시퀀스의 마지막 출력을 반환할지(False) 또는 전체 시퀀스를 반환할지(True). 기본값은 False입니다.
Practical Example
목표는 영화의 예고편 중에 어떤 장르가 나타나는지 확인하는 것입니다. 간단히 말하면, 가능한 장르는 코미디, 액션, 공포, 스릴러, 뮤지컬 또는 기타 총 6가지입니다. 예를 들어, 트레일러 장면에서 폭발이 발생한 경우 이를 액션으로 분류해야 합니다. 만약 다음 장면에 소름끼치는 광대가 있다면, 그것은 공포로 분류되어야 합니다.
모델 아키텍처
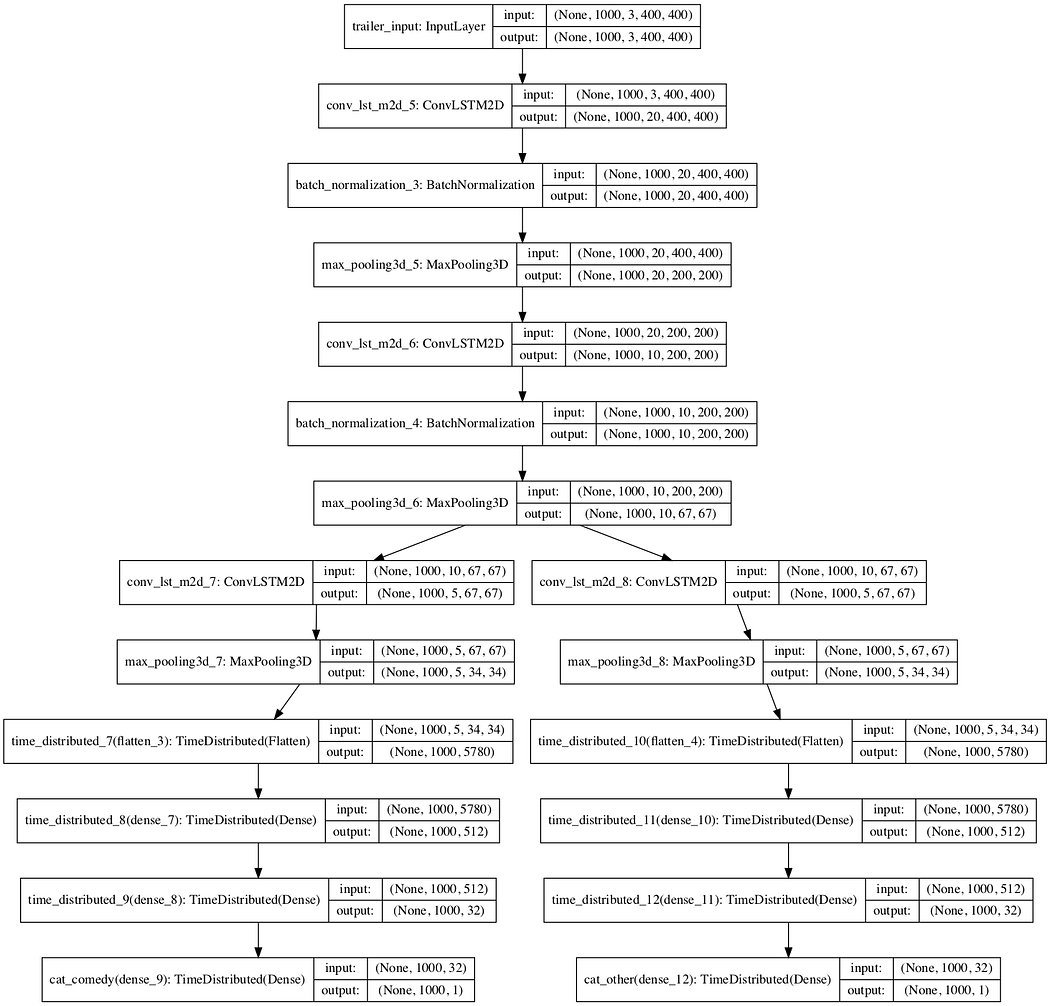
이 모델에는 단일 입력, 순차적인 트레일러 프레임 및 각 범주별로 하나씩 6개의 독립적인 출력이 있습니다.
모델 입력은 비디오입니다. 형식은 (샘플, 프레임, 채널, 행, 콜)입니다. 샘플당 프레임 수를 1000으로 제한하고 3채널 400x400픽셀 사진으로 이미지를 제한하는 입력 최종 형식은 (샘플, 1000, 3, 400, 400)입니다. 샘플은 교육에 사용할 수 있는 트레일러 수입니다.
이 예에서는 return_sample = True를 사용하므로 출력은 (범주, 프레임, 범주)이어야 하지만 모델에 6개의 독립적인 출력이 있으므로 출력은 (범주, 샘플, 프레임, 1) 더 정확하게 (6, 샘플, 1000, 1)입니다. return_sequences를 사용하면 모델이 각 프레임을 하나의 범주로 분류할 수 있습니다.
이 아키텍처는 두 개의 ConvLSTM 계층으로 시작하며, 각 계층은 배치 정규화와 최대 풀링으로 이어집니다. 순서대로 각 범주마다 하나씩 분기로 나뉩니다. 모든 분기는 동일하며, 하나의 ConvLSTM 계층으로 시작한 다음 MaxPooling으로 시작합니다. 그런 다음 이 출력은 완전히 연결된 고밀도 네트워크에 연결됩니다. 마지막으로, 마지막 레이어는 단일 셀이 있는 밀도입니다. 다음 이미지는 두 가지 범주(코미디 및 기타)만 있는 단순화된 모델을 보여줍니다.
def My_ConvLSTM_Model(frames, channels, pixels_x, pixels_y, categories):
trailer_input = Input(shape=(frames, channels, pixels_x, pixels_y)
, name='trailer_input')
first_ConvLSTM = ConvLSTM2D(filters=20, kernel_size=(3, 3)
, data_format='channels_first'
, recurrent_activation='hard_sigmoid'
, activation='tanh'
, padding='same', return_sequences=True)(trailer_input)
first_BatchNormalization = BatchNormalization()(first_ConvLSTM)
first_Pooling = MaxPooling3D(pool_size=(1, 2, 2), padding='same', data_format='channels_first')(first_BatchNormalization)
second_ConvLSTM = ConvLSTM2D(filters=10, kernel_size=(3, 3)
, data_format='channels_first'
, padding='same', return_sequences=True)(first_Pooling)
second_BatchNormalization = BatchNormalization()(second_ConvLSTM)
second_Pooling = MaxPooling3D(pool_size=(1, 3, 3), padding='same', data_format='channels_first')(second_BatchNormalization)
outputs = [branch(second_Pooling, 'cat_{}'.format(category)) for category in categories]
seq = Model(inputs=trailer_input, outputs=outputs, name='Model ')
return seq
def branch(last_convlstm_layer, name):
branch_ConvLSTM = ConvLSTM2D(filters=5, kernel_size=(3, 3)
, data_format='channels_first'
, stateful = False
, kernel_initializer='random_uniform'
, padding='same', return_sequences=True)(last_convlstm_layer)
branch_Pooling = MaxPooling3D(pool_size=(1, 2, 2), padding='same', data_format='channels_first')(branch_ConvLSTM)
flat_layer = TimeDistributed(Flatten())(branch_Pooling)
first_Dense = TimeDistributed(Dense(512,))(flat_layer)
second_Dense = TimeDistributed(Dense(32,))(first_Dense)
target = TimeDistributed(Dense(1), name=name)(second_Dense)
return target
교육
실제로 모델을 한 번에 공급하기 위해 여러 개의 비디오를 RAM에 업로드하는 것은 불가능합니다. 이러한 메모리 문제는 이미지로 작업할 때 매우 일반적입니다. 솔루션은 제너레이터를 사용하는 것입니다. 이를 통해 .fit()로 한꺼번에 공급하는 대신 .fit_generator()를 사용하여 모델 샘플을 샘플로 공급할 수 있습니다.
트레일러 데이터 집합이 사전 처리되고 파일별로 trailer_{id}.npy 형식으로 저장되며 ID는 0에서 num_trailers 사이의 숫자라고 가정합니다:
>>> np.load('dataset/scene_0.npy').shape()
(1000, 3, 400, 400)
>>> np.load('dataset/category_0.npy').shape()
(6, 1, 1000, 1)
모델에는 6개의 독립적인 출력이 있으며 각 출력은 (1, 1000, 1)인 형상(샘플, time_step, 1)을 갖는 3D 텐서를 예상합니다.
제너레이터는 다음과 같이 정의할 수 있습니다:
def generate_arrays(available_ids):
from random import shuffle
while True:
shuffle(available_ids)
for i in available_ids:
scene = np.load('dataset/scene_{}.npy'.format(i))
category = np.load('dataset/category_{}.npy'.format(i))
yield (np.array([scene]), category)
생성기는 교육에 사용할 수 있는 트레일러 ID 목록을 입력으로 수신하고 파일을 하나씩 로드한 후 (input, expected_output)로 반환하여 하나의 샘플로 모델을 교육합니다.
그런 다음 모델을 교육하기만 하면 됩니다:
# Train / Validation split
available_ids = [i for i in range(0, num_trailers)]
from random import shuffle
shuffle(available_ids)
final_train_id = int(len(available_ids)*0.8)
train_ids = available_ids[:final_train_id]
val_ids = available_ids[final_train_id:]
# fit the model
history = model.fit_generator(
generate_arrays(train_ids)
, steps_per_epoch = len(train_ids)
, validation_data = generate_arrays(val_ids)
, validation_steps = len(val_ids)
, epochs = 100
, verbose = 1
, shuffle = False
, initial_epoch = 0
)