여러 CNN 아키텍처(LeNet, GoogleNet, Alexnet, VGG, ResNet)
사전에 보면 좋은 것 :
마리나가 숙청 도중에 들고 나왔다는 CNN공부자료 (tistory.com)
마리나가 숙청 도중에 들고 나왔다는 CNN공부자료
https://89douner.tistory.com/57 3. CNN(Convolution Neural Network)는 어떤 구조인가요? 안녕하세요~ 이번글에서는 Convolution Neural Network(CNN)의 기본구조에 대해서 알아보도록 할거에요. CNN은 기본적으..
jwgdkmj.tistory.com
CNN의 컨볼루션 레이어는, 무작위 필터를 생성한 다음, 이미지를 훑으면서 그 필터와 유사한 특징을 지닌 부분을 찾아내는 것. 이를 통해 edge나 기타 feature을 찾아낼 수 있다.
1. LeNet
[Deep Learning, CNN, PyTorch Code] LeNet-5 (tistory.com)
[CNN 알고리즘들] LeNet-5의 구조 (bskyvision.com)

인풋 + 3개의 컨볼루션 레이어(C1, C3, C5) + 2개의 서브샘플링 레이어(S2, S4) + 1개의 fully connected layer(F6) + 아웃풋레이어 로 구성. 활성화함수 tanh
1) C1 레이어: 입력 영상(여기서는 32 x 32 사이즈의 이미지)을 6개의 5 x 5 필터와 컨볼루션 연산을 해준다. 그 결과 6장의 28 x 28 특성 맵을 얻게 된다.
훈련해야할 파라미터 수: (가중치*입력맵개수 + 바이어스)*특성맵개수 = (5*5*1 + 1)*6 = 156
2) S2 레이어: 6장의 28 x 28 특성 맵에 대해 서브샘플링을 진행한다. 결과적으로 28 x 28 사이즈의 특성 맵이 14 x 14 사이즈의 특성맵으로 축소된다. 2 x 2 필터를 stride 2로 설정해서 서브샘플링해주기 때문이다. 사용하는 서브샘플링 방법은 평균 풀링(average pooling)이다.
훈련해야할 파라미터 개수: (가중치 + 바이어스)*특성맵개수 = (1 + 1)*6 = 12
평균풀링인데 왜 훈련해야할 파라미터가 필요한지 의아할 수 있는데, original 논문에 의하면 평균을 낸 후에 한 개의 훈련가능한 가중치(trainable weight)를 곱해주고 또 한 개의 훈련가능한 바이어스(trainable bias)를 더해준다고 한다. 그 값이 시그모이드 함수를 통해 활성화된다. 참고로 그 가중치와 바이어스는 시그모이드의 비활성도를 조절해준다고 한다.
3) C3 레이어: 6장의 14 x 14 특성맵에 컨볼루션 연산을 수행해서 16장의 10 x 10 특성맵을 산출해낸다. 이는 아래의 과정을 보면 된다. X가, 사용되는 것.
열0-5) 6장의 14 x 14 특성맵에서 연속된 3장씩 모아서 5 x 5 x 3 사이즈의 필터와 컨볼루션. 6장의 10 x 10 특성맵이 산출.
열6-11) 6장의 14 x 14 특성맵에서 연속된 4장씩 모아서 5 x 5 x 4 사이즈의 필터와 컨볼루션. 6장의 10 x 10 특성맵 산출.
열12-14) 6장의 14 x 14 특성맵에서 불연속한 4장씩 모아 5 x 5 x 4 사이즈 필터와 컨볼루션. 3장의 10 x 10 특성맵 산출.
열15) 6장의 14 x 14 특성맵 모두를 가지고 5 x 5 x 6 사이즈의 필터와 컨볼루션. 1장의 10 x 10 특성맵이 산출.
결과적으로 16장(6 + 6 + 3 + 1)의 10 x 10 특성맵을 얻게 되었다.

훈련해야할 파라미터 개수:
첫번째그룹=> (가중치*입력맵개수+바이어스)*특성맵 개수 = (5*5*3 + 1)*6 = 456
두번째그룹=> (가중치*입력맵개수+바이어스)*특성맵 개수 = (5*5*4 + 1)*6 = 606
세번째그룹=> (가중치*입력맵개수+바이어스)*특성맵 개수 = (5*5*4 + 1)*3 = 303
네번째그룹=> (가중치*입력맵개수+바이어스)*특성맵 개수 = (5*5*6 + 1)*1 = 151
456 + 606 + 303 + 151 = 1516
4) S4 레이어: 16장의 10 x 10 특성 맵에 대해서 서브샘플링을 진행해 16장의 5 x 5 특성 맵으로 축소시킨다.
훈련해야할 파라미터 개수: (가중치 + 바이어스)*특성맵개수 = (1 + 1)*16 = 32
5) C5 레이어: 16장의 5 x 5 특성맵을 120개 5 x 5 x 16 사이즈의 필터와 컨볼루션 해준다. 결과적으로 120개 1 x 1 특성맵이 산출된다.
훈련해야할 파라미터 개수: (가중치*입력맵개수 + 바이어스)*특성맵 개수 = (5*5*16 + 1)*120 = 48120
6) F6 레이어: 84개의 유닛을 가진 피드포워드 신경망이다. C5의 결과를 84개의 유닛에 연결시킨다.
훈련해야할 파라미터 개수: 연결개수 = (입력개수 + 바이어스)*출력개수 = (120 + 1)*84 = 10164
7) 아웃풋 레이어: 10개의 Euclidean radial basis function(RBF) 유닛들로 구성되어있다. 각각 F6의 84개 유닛으로부터 인풋을 받는다. 최종적으로 이미지가 속한 클래스를 알려준다. 아웃풋레이어에 대해서는 맨 상단의 링크를 볼 것.
최종적으로, LeNet-5를 제대로 가동하기 위해 훈련해야할 파라미터는 156 + 12 + 1516 + 32 + 48120 + 10164 = 60000개.
2. Alexnet
[CNN 알고리즘들] AlexNet의 구조 (bskyvision.com)
[CNN 알고리즘들] AlexNet의 구조
LeNet-5 => https://bskyvision.com/418 AlexNet => https://bskyvision.com/421 VGG-F, VGG-M, VGG-S => https://bskyvision.com/420 VGG-16, VGG-19 => https://bskyvision.com/504 GoogLeNet(inception v1) =>..
bskyvision.com
Lenet에서, 2개의 gpu로 병렬연산을 수행하는 것이 큰 변화.
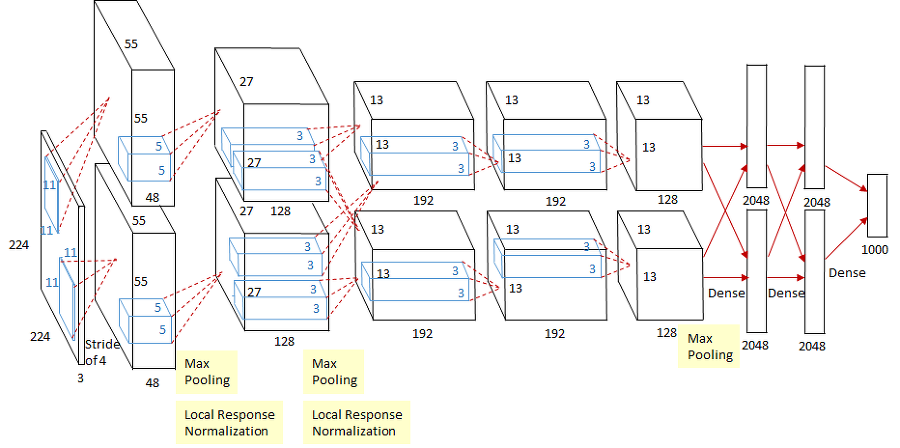
AlexNet : 5개의 컨볼루션 레이어 + 3개의 full-connected 레이어, 총 8개의 레이어로 구성.
두번째, 네번째, 다섯번째 컨볼루션 레이어들은 전 단계의 같은 채널의 특성맵들과만 연결되어 있는 반면,
세번째 컨볼루션 레이어는 전 단계의 두 채널의 특성맵들과 모두 연결되어 있다는 것을 볼 수 있다.
이제 각 레이어마다 어떤 작업이 수행되는지 살펴보자. 우선 AlexNet에 입력 되는 것은 227 x 227 x 3 이미지다.
1) 첫번째 레이어(컨볼루션 레이어): 96개의 11 x 11 x 3 사이즈 필터커널로 입력 영상을 컨볼루션.
컨볼루션 보폭(stride)를 4로 설정했고, zero-padding은 사용하지 않았다.
결과적으로 55 x 55 x 96 특성맵(96장의 55 x 55 사이즈 특성맵들)이 산출된다.
ReLU 함수로 활성화 후, overlapping max pooling이 stride 2로 시행된다. 그 결과 27 x 27 x 96 특성맵을 갖게 된다.
그 다음에는 수렴 속도를 높이기 위해 local response normalization이 시행된다. local response normalization은 특성맵의 차원을 변화시키지 않으므로, 특성맵의 크기는 27 x 27 x 96으로 유지된다.
이 local response normalization(LRN)은,
AlexNet: ImageNet Classification wtih Deep Convolutional Neural Networks
AlexNet ImageNet Classification wtih Deep Convolutional Neural Networks AlexNet: ImageNet Classification wtih Deep Convolutional Neural Networks 2012년에 쓰여진 논문으로서 그때 작은 크기의 Dataset에..
curaai00.tistory.com
즉, ReLU를 사용했는데, 너무 큰 값이 나왔고, 이로 인해 Max pooling등을 할 때 나머지에 너무 큰 관여를 하게될 수 있으니, 다른 ActivationMap의 같은 위치에 있는 픽셀끼리 정규화를 한다는 뜻.
2) 두번째 레이어(컨볼루션 레이어): 256개의 5 x 5 x 48 커널을 사용하여 전 단계의 특성맵을 컨볼루션해준다.
stride는 1로, zero-padding은 2로 설정했다.
따라서 27 x 27 x 256 특성맵(256장의 27 x 27 사이즈 특성맵들)을 얻게 된다. 역시 ReLU 함수로 활성화한다.
그 다음에 3 x 3 overlapping max pooling을 stride 2로 시행한다. 그 결과 13 x 13 x 256 특성맵을 얻게 된다.
그 후 local response normalization이 시행되고, 특성맵의 크기는 13 x 13 x 256으로 그대로 유지된다.
3) 세번째 레이어(컨볼루션 레이어): 384개의 3 x 3 x 256 커널을 사용하여 전 단계의 특성맵을 컨볼루션해준다.
stride와 zero-padding 모두 1로 설정한다.
따라서 13 x 13 x 384 특성맵(384장의 13 x 13 사이즈 특성맵들)을 얻게 된다.
역시 ReLU 함수로 활성화한다.
4) 네번째 레이어(컨볼루션 레이어): 384개의 3 x 3 x 192 커널을 사용해서 전 단계의 특성맵을 컨볼루션해준다.
stride와 zero-padding 모두 1로 설정한다.
따라서 13 x 13 x 384 특성맵(384장의 13 x 13 사이즈 특성맵들)을 얻게 된다.
역시 ReLU 함수로 활성화한다.
5) 다섯번째 레이어(컨볼루션 레이어): 256개의 3 x 3 x 192 커널을 사용해서 전 단계의 특성맵을 컨볼루션해준다.
stride와 zero-padding 모두 1로 설정한다.
따라서 13 x 13 x 256 특성맵(256장의 13 x 13 사이즈 특성맵들)을 얻게 된다.
역시 ReLU 함수로 활성화한다.
그 다음에 3 x 3 overlapping max pooling을 stride 2로 시행한다.
그 결과 6 x 6 x 256 특성맵을 얻게 된다.
6) 여섯번째 레이어(Fully connected layer): 6 x 6 x 256 특성맵을 flatten해서 6 x 6 x 256 = 9216차원의 벡터로 만든다. 그것을 여섯번째 레이어의 4096개의 뉴런과 fully connected 해준다. 그 결과를 ReLU 함수로 활성화한다.
7) 일곱번째 레이어(Fully connected layer): 4096개의 뉴런으로 구성되어 있다.
전 단계의 4096개 뉴런과 fully connected되어 있다. 출력 값은 ReLU 함수로 활성화된다.
8) 여덟번째 레이어(Fully connected layer): 1000개의 뉴런으로 구성되어 있다.
전 단계의 4096개 뉴런과 fully connected되어 있다. 1000개 뉴런의 출력값에 softmax를 적용해 1000개 클래스 각각에 속할 확률을 나타낸다.
즉, 2개의 GPU로 평범하게 돌린 다음, 두 개의 결과를 합쳐 Softmax시키는 것이다.
ReLU, 드롭아웃, Overlapping pooling, LRN, Data Augmentaion등을 활용했다.
3. VGG
[CNN 알고리즘들] VGGNet의 구조 (VGG16) (bskyvision.com)
[CNN 알고리즘들] VGGNet의 구조 (VGG16)
LeNet-5 => https://bskyvision.com/418 AlexNet => https://bskyvision.com/421 VGG-F, VGG-M, VGG-S => https://bskyvision.com/420 VGG-16, VGG-19 => https://bskyvision.com/504 GoogLeNet(inception v1) =>..
bskyvision.com
이 연구의 핵심은 네트워크의 깊이를 깊게 만드는 것이 성능에 어떤 영향을 미치는지를 확인하고자 한 것이다. 오직 깊이의 영향만을 최대한 확인하고자, 필터커널의 사이즈는 가장 작은 3 x 3으로 고정했다. 필터커널의 사이즈가 크면 그만큼 이미지의 사이즈가 금방 축소되기 때문에 네트워크의 깊이를 충분히 깊게 만들기 불가능하다.
VGGNet의 구조를 깊이 들여다보기에 앞서 먼저 집고 넘어가야할 것이 있다. 그것은 바로 3 x 3 필터로 두 차례 컨볼루션을 하는 것과 5 x 5 필터로 한 번 컨볼루션을 하는 것이 결과적으로 동일한 사이즈의 특성맵을 산출한다는 것이다(아래 그림 참고). 3 x 3 필터로 세 차례 컨볼루션 하는 것은 7 x 7 필터로 한 번 컨볼루션 하는 것과 대응된다.

그러면 3 x 3 필터로 세 차례 컨볼루션을 하는 것이 7 x 7 필터로 한 번 컨볼루션하는 것보다 나은 점은 무엇일까? 일단 가중치 또는 파라미터의 갯수의 차이다. 3 x 3 필터가 3개면 총 27개의 가중치를 갖는다. 반면 7 x 7 필터는 49개의 가중치를 갖는다. CNN에서 가중치는 모두 훈련이 필요한 것들이므로, 가중치가 적다는 것은 1) 그만큼 훈련시켜야할 것의 갯수가 적어지기에, 학습의 속도가 빨라진다. 동시에 2) 층의 갯수가 늘어나면서 특성에 비선형성을 더 증가시키기 때문에 특성이 점점 더 유용해진다.

0) 인풋: 224 x 224 x 3 이미지(224 x 224 RGB 이미지)를 입력받을 수 있다.
1) 1층(conv1_1): 64개의 3 x 3 x 3 필터커널로 입력이미지를 컨볼루션해준다. zero padding은 1만큼 해줬고, 컨볼루션 보폭(stride)는 1로 설정해준다. 이후 zero padding과 컨볼루션 stride에 대한 설정은 모든 컨볼루션층에서 모두 동일하다. 결과적으로 64장의 224 x 224 특성맵(224 x 224 x 64)들이 생성된다. 활성화시키기 위해 ReLU 함수가 적용된다. ReLU함수는 마지막 16층을 제외하고는 항상 적용되니 이 또한 다음 층부터는 설명을 생략하겠다.
2) 2층(conv1_2): 64개의 3 x 3 x 64 필터커널로 특성맵을 컨볼루션해준다. 결과적으로 64장의 224 x 224 특성맵들(224 x 224 x 64)이 생성된다. 그 다음에 2 x 2 최대 풀링을 stride 2로 적용함으로 특성맵의 사이즈를 112 x 112 x 64로 줄인다.
3) 3층(conv2_1): 128개의 3 x 3 x 64 필터커널로 특성맵을 컨볼루션해준다. 즉, 3 x 3 짜리 128장의 필터로, 112 x 112 짜리 feature map을 64장을 학습시켜, 224 x 224짜리 64장을 만들겠다는 뜻. 결과적으로 128장의 112 x 112 특성맵들(112 x 112 x 128)이 산출된다.
4) 4층(conv2_2): 128개의 3 x 3 x 128 필터커널로 특성맵을 컨볼루션해준다. 결과적으로 128장의 112 x 112 특성맵들(112 x 112 x 128)이 산출된다. 그 다음에 2 x 2 최대 풀링을 stride 2로 적용해준다. 특성맵의 사이즈가 56 x 56 x 128로 줄어들었다.
5) 5층(conv3_1): 256개의 3 x 3 x 128 필터커널로 특성맵을 컨볼루션한다. 결과적으로 256장의 56 x 56 특성맵들(56 x 56 x 256)이 생성된다.
6) 6층(conv3_2): 256개의 3 x 3 x 256 필터커널로 특성맵을 컨볼루션한다. 결과적으로 256장의 56 x 56 특성맵들(56 x 56 x 256)이 생성된다.
7) 7층(conv3_3): 256개의 3 x 3 x 256 필터커널로 특성맵을 컨볼루션한다. 결과적으로 256장의 56 x 56 특성맵들(56 x 56 x 256)이 생성된다. 그 다음에 2 x 2 최대 풀링을 stride 2로 적용한다. 특성맵의 사이즈가 28 x 28 x 256으로 줄어들었다.
8) 8층(conv4_1): 512개의 3 x 3 x 256 필터커널로 특성맵을 컨볼루션한다. 결과적으로 512장의 28 x 28 특성맵들(28 x 28 x 512)이 생성된다.
9) 9층(conv4_2): 512개의 3 x 3 x 512 필터커널로 특성맵을 컨볼루션한다. 결과적으로 512장의 28 x 28 특성맵들(28 x 28 x 512)이 생성된다.
10) 10층(conv4_3): 512개의 3 x 3 x 512 필터커널로 특성맵을 컨볼루션한다. 결과적으로 512장의 28 x 28 특성맵들(28 x 28 x 512)이 생성된다. 그 다음에 2 x 2 최대 풀링을 stride 2로 적용한다. 특성맵의 사이즈가 14 x 14 x 512로 줄어든다.
11) 11층(conv5_1): 512개의 3 x 3 x 512 필터커널로 특성맵을 컨볼루션한다. 결과적으로 512장의 14 x 14 특성맵들(14 x 14 x 512)이 생성된다.
12) 12층(conv5_2): 512개의 3 x 3 x 512 필터커널로 특성맵을 컨볼루션한다. 결과적으로 512장의 14 x 14 특성맵들(14 x 14 x 512)이 생성된다.
13) 13층(conv5-3): 512개의 3 x 3 x 512 필터커널로 특성맵을 컨볼루션한다. 결과적으로 512장의 14 x 14 특성맵들(14 x 14 x 512)이 생성된다. 그 다음에 2 x 2 최대 풀링을 stride 2로 적용한다. 특성맵의 사이즈가 7 x 7 x 512로 줄어든다.
14) 14층(fc1): 7 x 7 x 512의 특성맵을 flatten 해준다. flatten이라는 것은 전 층의 출력을 받아서 단순히 1차원의 벡터로 펼쳐주는 것을 의미한다. 결과적으로 7 x 7 x 512 = 25088개의 뉴런이 되고, fc1층의 4096개의 뉴런과 fully connected 된다. 훈련시 dropout이 적용된다.
(이 부분을 제대로 이해할 수 있도록 지적해주신 jaist님과 hiska님께 감사드립니다.^^)
15) 15층(fc2): 4096개의 뉴런으로 구성해준다. fc1층의 4096개의 뉴런과 fully connected 된다. 훈련시 dropout이 적용된다.
16) 16층(fc3): 1000개의 뉴런으로 구성된다. fc2층의 4096개의 뉴런과 fully connected된다. 출력값들은 softmax 함수로 활성화된다. 1000개의 뉴런으로 구성되었다는 것은 1000개의 클래스로 분류하는 목적으로 만들어진 네트워크란 뜻이다.
4. GoolgleNet

위처럼 인풋채널이 3개면, Convolution연산의 필터 채널 역시 3개가 필요.
이 필터의 개수에 따라 아웃풋 채널 개수가 결정됨.
인풋의 채널 수 = 필터의 채널 수 && 필터의 갯수 = 아웃풀의 채널 수
또한, 인풋채널과 필터의 연산과정은, 최종적으로 한 개의 값으로 모두 더해지게 됨.
모바일넷의 요지는, 왜 3채널 모두에 연산을 해야 하는가?

Depthwise convolution은, 입력값의 가장 앞 채널인 붉은 3x3 영역만 필터와 연산이 되어, 동일한 위치에 스칼라값으로 출력. 녹색과 파란색 역시, 동일한 위치에 스칼라값으로 출력됨.
채널 방향의 연산은, Pointwise Convolution에서 1x1 convolution 적용을 통해 하며, 최종적으로 연산 수가 감소한다.
정확히 어떻게 줄어든다는 건데?
- 인풋을 받으면, 그 인풋을 depth(채널) 별로 나눈 다음
- 각 채널과 그에 해당하는 3x3 필터를 convolution연산한다. 즉, 인풋의 채널수 만큼 3 x 3 필터가 존재
- convolution 연산을 마친 feature map을 다시 stacking.
- 이 결과물을 다시 1x1 convolution을 해준다. 이때, 1채널의 매트릭스가 결과물로 나오게 된다.
- 이 1x1 convolution이 N개이면, N번 연산을 통해 N개의 매트릭스가 결과물로 나오게 되고, 그것을 stacking하면 volume형태의 output이 됨.
https://eehoeskrap.tistory.com/431


채널 방향의 Convolution 은 진행하지 않고, 공간 방향의 Convolution 만을 진행했다.
즉, 각 커널들은 하나의 채널에 대해서만 파라미터를 가진다. 그래서 입력 및 출력 채널의 수가 동일한 것이며 각 채널 고유의 Spatial 정보만을 사용하여 필터를 학습하게 된다.

장단점) mAP는 다소 떨어지지만 확실히 연산량과 파라미터 수에서 효율적
구글 인셉션 Google Inception(GoogLeNet) 알아보기 (tistory.com)
구글 인셉션 Google Inception(GoogLeNet) 알아보기
이번에 알아볼 내용은 하나의 논문을 공부하는 것은 아니지만 유명한 뉴럴네트워크인 구글의 GoogLeNet에 대해 알아보겠습니다. 직접 딥러닝/머신러닝 아키텍처와 알고리즘들을 구현하지 않고 편
ikkison.tistory.com

1 x 1 컨벌루션은, 채널 수가 감소했다 증가하는 병목현상을 보여주면서, 동시에 param 수를 획기적으로 감소시킨다.
[CNN 알고리즘들] GoogLeNet(inception v1)의 구조
LeNet-5 => https://bskyvision.com/418 AlexNet => https://bskyvision.com/421 VGG-F, VGG-M, VGG-S => https://bskyvision.com/420 VGG-16, VGG-19 => https://bskyvision.com/504 GoogLeNet(inception v1) =>..
bskyvision.com
https://ikkison.tistory.com/86
구글 인셉션 Google Inception(GoogLeNet) 알아보기
이번에 알아볼 내용은 하나의 논문을 공부하는 것은 아니지만 유명한 뉴럴네트워크인 구글의 GoogLeNet에 대해 알아보겠습니다. 직접 딥러닝/머신러닝 아키텍처와 알고리즘들을 구현하지 않고 편
ikkison.tistory.com
이러한 기초에 기반해보자면,

곳곳에 1x1 convolution 층을 끼워놓았다.
또한 Inception이라 불리는 모듈들 역시 끼워놓았는데,

그 구조는 아래와 같다.

GoogLeNet에 실제로 사용된 모듈은 특성맵의 장의 수를 줄여주는 1x1 컨볼루션(노랑)이 포함된 (b) 모델이다. 아까 살펴봤듯이 1x1 컨볼루션은 특성맵의 장수를 줄여주는 역할을 한다. 이를 제외한 나이브(naive) 버전을 살펴보면, 이전 층에서 생성된 특성맵을 1x1 컨볼루션, 3x3 컨볼루션, 5x5 컨볼루션, 3x3 최대풀링해준 결과 얻은 특성맵들을 모두 함께 쌓아준다(Concatenation). 말 그대로, feature map을 효과적으로 찾기 위해 다양한 커널로 추출을 한 뒤, 그 결과들을 쌓아주는 기능이다.
AlexNet, VGGNet 등의 이전 CNN 모델들은 한 층에서 동일한 사이즈의 필터커널을 이용해서 컨볼루션을 해줬던 것과 차이가 있다. 따라서 좀 더 다양한 종류의 특성이 도출된다.
여기에 1x1 컨볼루션이 포함되었으니 당연히 연산량은 많이 줄어들었을 것이다.
3) global average pooling
AlexNet, VGGNet 등에서는 fully connected (FC) 층들이 망의 후반부에 연결되어 있다. 그러나 GoogLeNet은 FC 방식 대신에 global average pooling이란 방식을 사용한다. global average pooling은 전 층에서 산출된 특성맵들을 각각 평균낸 것을 이어서 1차원 벡터를 만들어주는 것이다. 1차원 벡터를 만들어줘야 최종적으로 이미지 분류를 위한 softmax 층을 연결해줄 수 있기 때문이다. 만약 전 층에서 1024장의 7 x 7의 특성맵이 생성되었다면, 1024장의 7 x 7 특성맵 각각 평균내주어 얻은 1024개의 값을 하나의 벡터로 연결해주는 것이다.

이렇게 해줌으로 얻을 수 있는 장점은 가중치의 갯수를 상당히 많이 없애준다는 것이다. 최종적으로 마지막 Concetation과정에서, 1x1이나 3x3을 합쳐 쌓아올려 7 x 7 x 1024짜리 특성맵들을 만들어냈을 때, 만약 FC 방식을 사용한다면 훈련이 필요한 가중치의 갯수가 7 x 7 x 1024 x 1024 = 51.3M이지만 global average pooling을 사용하면 가중치가 단 한개도 필요하지 않다.
4) auxiliary classifier
네트워크의 깊이가 깊어지면 깊어질수록 역전파과정에서 가중치를 업데이트하는데 사용되는 gradient가 점점 작아져서 0이 되어버리는 등, 잘 학습이 되지 않을 수 있다. 이 문제를 극복하기 위해서 GoogLeNet에서는 네트워크 중간에 두 개의 보조 분류기(auxiliary classifier)를 달아주었다.

보조 분류기(softmax)의 구성을 살펴보면, 5 x 5 평균 풀링(stride 3) -> 128개 1x1 필터커널로 컨볼루션 -> 1024 FC 층 -> 1000 FC 층 -> softmax 순이다. 해당 분류기에서 계산된 error값은 0.3이란 가중치와 곱해져 최종 error에 더해진다. 이 보조 분류기들은 훈련시에만 활용되고 사용할 때는 제거해준다.
5. ResNet
[CNN 알고리즘들] ResNet의 구조
LeNet-5 => https://bskyvision.com/418 AlexNet => https://bskyvision.com/421 VGG-F, VGG-M, VGG-S => https://bskyvision.com/420 VGG-16, VGG-19 => https://bskyvision.com/504 GoogLeNet(inception v1) =>..
bskyvision.com
망이 훨씬 더 깊어졌다. 그러나 망을 깊게 하는 것이 능사는 아니기에, 거기에 뭔가를 더 추가한 모양새.
Residual Block
그것이 바로 ResNet의 핵심인 Residual Block의 출현을 가능케 했다. 아래 그림에서 오른쪽이 Residual Block을 나타낸다. 기존의 망과 차이가 있다면 입력값을 출력값에 더해줄 수 있도록 지름길(shortcut)을 하나 만들어준 것 뿐이다.

기존의 신경망(왼쪽)은 입력값(input) x를 타겟값(target, 즉 정답) y로 매핑하는 함수 H(x)를 얻는 것이 목적이었다. 그러나 ResNet은 F(x) + x를 최소화하는 것을 목적으로 한다. x는 현시점에서 변할 수 없는 값이므로 F(x)를 0에 가깝게 만드는 것이 목적이 된다. F(x)가 0이 되면 출력과 입력이 모두 x로 같아지게 된다. F(x) = H(x) - x이므로 F(x)를 최소로 해준다는 것은 H(x) - x를 최소로 해주는 것과 동일한 의미를 지닌다. 여기서 H(x) - x를 잔차(residual)라고 한다. 즉, 잔차를 최소로 해주는 것이므로 ResNet이란 이름이 붙게 된다.
보면 알겠지만, 단순히 weight layer을 통해 나온 결과와 그 전 결과를 더하고, relu를 사용한 것 뿐이다.
그리고 이를 F(x)가 0이 되도록 학습시키는 것 뿐이다.
ResNet의 구조
ResNet은 기본적으로 VGG-19의 구조를 뼈대로 한다. 거기에 컨볼루션 층들을 추가해서 깊게 만든 후에, shortcut들을 추가하는 것이 사실상 전부다. 34층의 ResNet과 거기에서 shortcut들을 제외한 버전인 plain 네트워크의 구조는 다음과 같다.
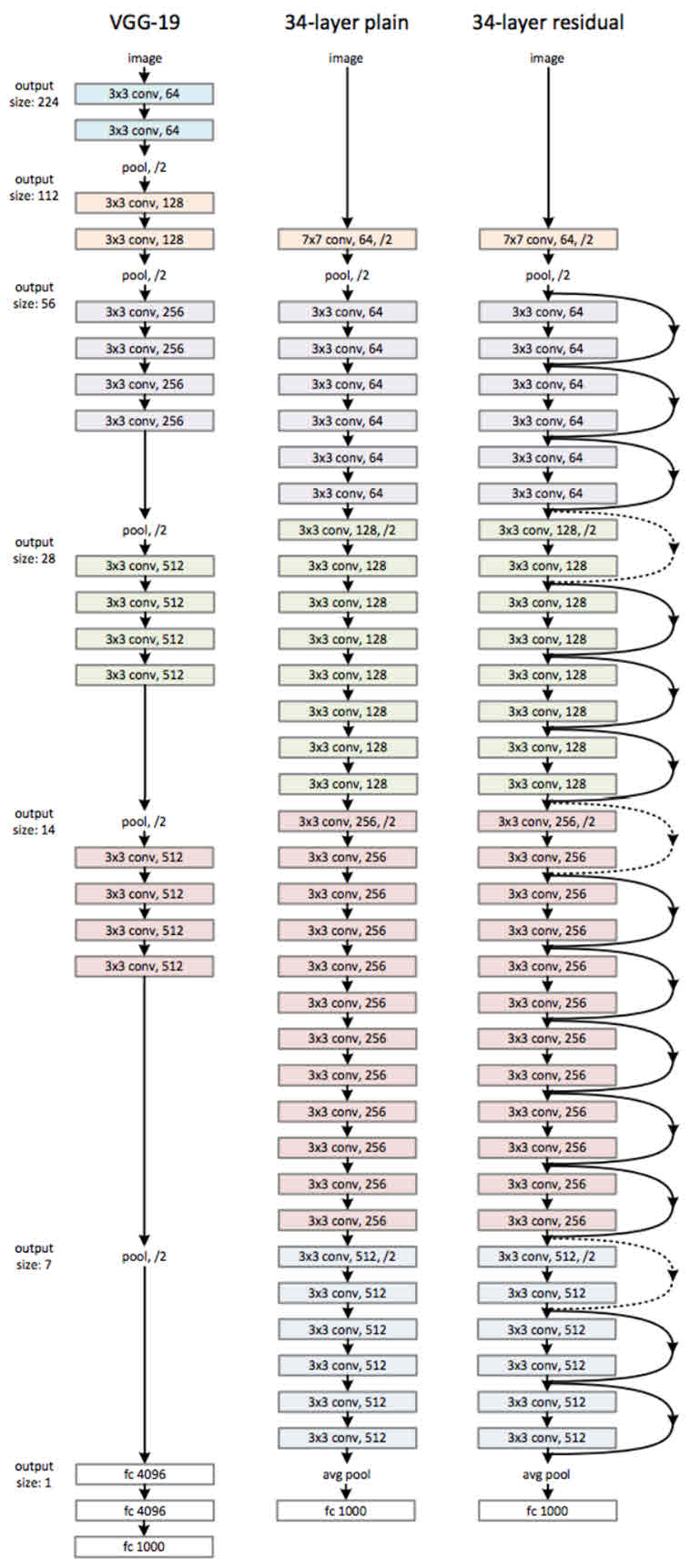
위 그림을 보면 알 수 있듯이 34층의 ResNet은 처음을 제외하고는 균일하게 3 x 3 사이즈의 컨볼루션 필터를 사용했다. 그리고 특성맵의 사이즈가 반으로 줄어들 때, 특성맵의 뎁스를 2배로 높였다.
저자들은 과연 shortcut, 즉 Residual block들이 효과가 있는지를 알기 위해 이미지넷에서 18층 및 34층의 plain 네트워크와 ResNet의 성능을 비교했다.
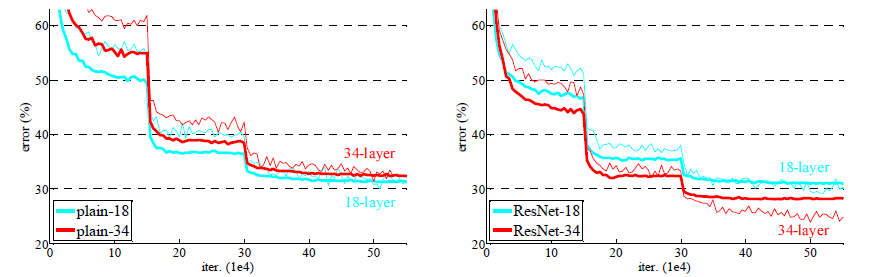
왼쪽 그래프를 보면 plain 네트워크는 망이 깊어지면서 오히려 에러가 커졌음을 알 수 있다. 34층의 plain 네트워크가 18층의 plain 네트워크보다 성능이 나쁘다. 반면, 오른쪽 그래프의 ResNet은 망이 깊어지면서 에러도 역시 작아졌다! shortcut을 연결해서 잔차(residual)를 최소가 되게 학습한 효과가 있다는 것이다.
즉, 핵심 아이디어는 층을 무지하게 많이 쌓고, 거기에 shortcut을 추가한 것.
그래서 그 계산은 어떻게 하는데?
https://m.blog.naver.com/laonple/221259295035
8. CNN 구조 3 - VGGNet, ResNet
안녕하세요, 라온피플(주)입니다. 아래와 같이 총 19회의 포스팅을 통해 Deep Learning 알고리즘에 대해 ...
blog.naver.com
2015년 발표된 ResNet는,
H(x) = ReLU(F(x) + x)) 이다.


