https://89douner.tistory.com/57
3. CNN(Convolution Neural Network)는 어떤 구조인가요?
안녕하세요~ 이번글에서는 Convolution Neural Network(CNN)의 기본구조에 대해서 알아보도록 할거에요. CNN은 기본적으로 Convolution layer-Pooling layer-FC layer 순서로 진행이 되기 때문에 이에 대해서 차..
89douner.tistory.com
여태 filter의 개수를 잘 이해 못 했는데, 이를 보고 이해함.
1) 여러 filter의 개수가 필요한 이유
2) filter가 특정 에지 등 특징지을만한 요소를 찾는 것이 주요 관건이라면, 이것이 계속 갱신되는 것은 어떤 의미가 있는가?
convolutional filter는, 하나의 이미지를 차례대로 훑으면서 특징값을 추출한다.
그럼 전체 이미지에서, 해당 filter와 유사한 모양을 가진 부분에 대한 feature의 획득이 가능할 것이다.
이를 통해, 특정 filter에 부합하는 feature 정보의 획득이 가능하다.
1) First Convolutional Layer
CNN에서, 물체의 윤곽을 알아내기 위해 가장 처음에 하는 것은 edge filter 사용이다.
한데 이 필터는 대체로 이미지에 비해 작기에, filter가 이미지를 커버할 수 있는 부분은 '선'과 같은 단순정보다.
이렇게 첫 번째 레이어에서 n개의 필터를 사용하면, 선과 같은 단순 정보를 담은 n개의 feature map이 나오게 된다.

이렇게 연두색 부분을 획득하게 되었다. 각각의 feature map은, 각각의 convolutional filter에 부합하는 feature 정보가 담겨있다.
이 filter은 학습을 통해, 점차 무작위 분포에서 완성된 edge filter로 만들어질 것이다.
2) Pooling Layer
Input - (conv - ReLU - pool) - (conv - ReLU - pool) .... - (Affine - softmax) 의 과정을 거칠 텐데,
max pooling을 통해 그 부분에서 가장 큰 값을 획득한다.
그렇다면 size가 작아지겠지.... 이는 곧 filter의 상대적 크기가 커짐을 의미한다!
따라서 보다 더 구체적인 feature을 얻을 수 있다는 뜻이기도 하지.
이렇게 자꾸 하다 보면, layer가 깊어질 수록 abstarct feature의 추출이 가능해진다.

밑 그림을 보면, 첫 번째와 두 번째 convolutional layer에서는 각각 6, 16개의 filter가 사용되었음을 알 수 있다.
두 번째 convolutional filter 하나는 이전에 얻은 6개의 feature map을 다 훑고 지나가겠지...
그럼 이렇게 총 6개의 feature map을 합산한 하나의 feature map을 만들게 되고,
이렇게 총 16개의, 6개의 이전 단계에서 만들어진 feature map이 합쳐진 새로운 feature map이 만들어진다.
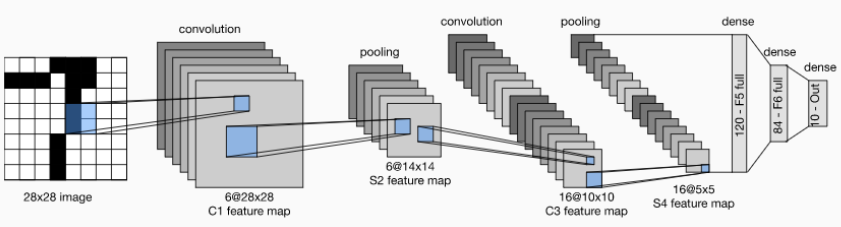
예시
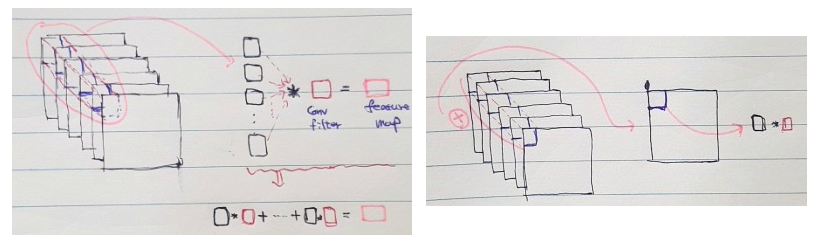
3) FC Layer
이를 진행하다 보면, 유사한 형태의 feature map이 선별되게 될 거다.
그럼 이제 유사한 것들을 분류해야겠지...
마지막 feature map을 일렬로 늘린 후, 이를 하나의 Hidden layer을 거쳐 DNN(MLP)를 통해 분류하게 된다.

분류 과정 : 최종적으로 완성된 것들을 1차원으로 늘리는 Flatten을 한 다음,
한 노드가 다음 층의 모든 노드들과 연결되어 있는 Fully connected layer을 구성.
다음으로, ReLU와 같은 활성화함수를 적용한 다음, softmax를 통해 최종적으로 구별한다.
이 softmax통한 구별값은 각각 0~1사이의 확률로 나타나며, 각각 하나의 객체일 확률을 나타낸다.


그럼 이제 이 filter은 어떻게 개선될까?
위의 분류 말고도, 정답(훈련 데이터셋)이 따로 있겠지.
위의 '임의의 필터'를 통해 만들어진 것과 정답 간의 손실함수를 구한다.
역전파를 구하는 식이나, o(output) = x * w에 대한 것은 다음 글 참조.
완전연결은, data의 형상을 무시하고 1차원적으로 나간다.
2차원 이미지는 상하좌우에 비슷한 이미지가 있을 확률이 큰데, 이를 1차원으로 나열하면 데이터 형상이 무너지고, 연산은 비효율적이게 됨. 따라서 CNN으로 하는게 낫다.
LeNet: (합성곱-풀링)을 반복해, 마지막에 완전연결시킴.
일반적인 CNN은 ReLU와 최대풀링을 쓰지만, 여기선 시그모이드와 서브샘플링을 사용.
AlexNet: 드롭아웃과 ReLU 사용
VGG : 합성곱계층 & 풀링으로 구성.
3*3의 작은 필터를 사용한 합성곱계층을 연속 거침.
이를 통해, 크기를 절반으로 줄이고, 마지막엔 fully-connected-layer을 통과시켜 결과를 출력
구글넷 : 가로방향에 폭(=인셉션 구조)가 있어, 크기가 다른 필터와 풀링을 여러 개 사용 후, 결과를 결합
ResNet : '스킵 연결'을 이용, 층의 깊이에 비례해 성능을 향상.
입력 x를 여녹한 두 합성곱 계층을 건너뛰어 출력에 연결.
이 단축경로가 없다면 두 합성곱 계층의 출력은 F(x). 근데 스킵연결로 F(x)+x가 됨.
즉, 입력 data를 그대로 흘린다. 역전파 역시 그냥 흘림으로써, 스킵 연결로 기울기가 작아지거나 커질 걱정 없이, 앞층의 '의미있는 기울기'가 그대로 전해짐
SegNet : 자율주행에 씀. 주변환경 인식
Deep Q-Network(DQN): 최적행동 가치 학습.
완전 연결 계층, Fully connected layer - 데이터 사이언스 사용 설명서 (tistory.com)
'버츄얼유튜버' 카테고리의 다른 글
| 이미지분류 위한 공부 (0) | 2022.04.08 |
|---|---|
| 카스미자와미유가 쓰레기통에서 줏은 머신러닝 관련 글 (0) | 2022.04.02 |
| selective search & 현대모비스 1차면접 ppt용 (2) | 2022.02.04 |
| 호시노가 낮잠자면서도 이해하는 R-CNN (0) | 2022.02.04 |
| 바보♡ 허접♡ 코하루도 이해하는 욜로(YOLO) (2) | 2022.01.29 |
