1. Yolov7x 기반으로 변경
2. Swin-T를 CSWin-T로 변경
3. 수가 적거나 잘 잡히지 않는 object에 대해 copy&paste 실행
4. Loss를 Generalized Focal loss로 변경?
Object Detection – VISDRONE (aiskyeye.com)
Object Detection – VISDRONE
Overview We are pleased to announce the VisDrone 2023 Object Detection in Images Challenge (Task 1). This competition is designed to push the state-of-the-art in object detection with drone platform forward. Teams are required to predict the bounding boxes
aiskyeye.com
데이터 확대는 실무자가 실제로 새로운 데이터를 수집하지 않고도 교육 모델에 사용할 수 있는 데이터의 다양성을 크게 높일 수 있는 전략입니다. 자르기, 패딩 및 수평 뒤집기와 같은 데이터 확대 기술은 일반적으로 딥 러닝 모델을 훈련하는 데 사용됩니다.
개체 탐지 작업의 경우 일반적으로 다음과 같은 확대 기법이 사용됩니다:
1. **Random Horizontal Flip**: 이미지를 수평으로 뒤집는 일반적인 확대 기법입니다. 이는 수직 축을 따라 입력의 미러 이미지를 촬영하는 것과 같습니다.
2. **랜덤 자르기**: 이 기법에서는 이미지의 일부를 랜덤하게 선택하여 원래 이미지 크기로 크기를 조정합니다. 이를 통해 모델은 다양한 위치와 척도의 물체를 감지하는 방법을 배울 수 있습니다.
3. **무작위 회전**: 영상이 일정한 각도로 무작위로 회전합니다. 이것은 모델이 다른 방향의 물체를 인식하는 것을 배우는 데 도움이 됩니다.
4. **랜덤 밝기, 대비, 채도 및 색상**: 색상 지터 기법입니다. 그들은 이미지의 색상을 변경하여 모델이 다양한 조명 조건에 강해지는 데 도움이 됩니다.
5. **랜덤 스케일링**: 이미지가 특정 요인에 의해 무작위로 스케일링되어 이미지에 있는 개체의 크기가 변경됩니다.
6. **랜덤 변환**: 이미지가 임의의 방향으로 이동합니다. 이를 통해 모델이 서로 다른 위치에 있는 물체를 감지하는 방법을 배울 수 있습니다.
7. **컷아웃/랜덤 소거**: 이미지의 임의 섹션이 흑백/노이즈 픽셀로 대체됩니다.
8. **혼합/컷 혼합**: 이러한 기술은 서로 다른 이미지의 일부를 함께 결합하는 고급 기술입니다.
데이터 확대 기술의 선택은 특정 작업과 데이터의 특성에 따라 달라집니다. 다양한 기술을 사용하여 특정 사용 사례에 가장 적합한 방법을 실험하는 것이 좋습니다.
과제가 추가적인 교육 데이터와 사전 교육된 모델을 사용할 수 있게 되면 성과를 개선할 수 있는 많은 가능성이 열립니다. 다음과 같이 접근할 수 있습니다:
1. **사전 교육된 모델**: 사전 교육된 모델을 사용하면 상당한 우위를 점할 수 있습니다. 이러한 모델은 ImageNet과 같은 대규모 데이터 세트에 대해 교육을 받았으며 다양한 기능을 인식하는 방법을 배웠습니다. 이러한 모델을 시작점으로 사용하여 챌린지 데이터에서 미세 조정할 수 있습니다. 이는 모델을 처음부터 교육하는 것보다 훨씬 빠르고 효과적인 경우가 많습니다. 객체 감지를 위한 일반적인 사전 교육 모델에는 YOLO, Faster R-CNN 및 SSD가 포함됩니다.
2. **추가 교육 데이터**: 제공된 교육 데이터가 제한적인 경우 추가 데이터를 사용하면 모델의 성능을 향상시킬 수 있습니다. 이는 다른 공용 데이터셋이거나 사용자가 직접 수집한 데이터일 수 있습니다. 핵심은 추가 데이터가 과제 데이터와 관련이 있고 유사한지 확인하는 것입니다. 또한 도전 데이터를 희생하면서 추가 데이터에 과도하게 적합하는 것에 대해서도 주의해야 합니다.
3. **데이터 확대**: 추가 데이터를 찾을 수 없거나 과제 규칙에 따라 외부 데이터 사용이 제한되는 경우 제공된 데이터를 확대하여 합성 데이터를 생성할 수 있습니다. 여기에는 회전, 스케일링, 뒤집기, 자르기 또는 노이즈 추가와 같은 변형이 포함될 수 있습니다.
4. **앙상블 모델**: 다양한 아키텍처를 사용하거나 다양한 데이터에 대해 교육을 받은 여러 모델을 교육하고 예측을 결합할 수 있습니다. 이로 인해 단일 모델보다 성능이 향상되는 경우가 많습니다.
5. **후 처리**: 과제에 따라 후 처리를 통해 예측을 개선할 수 있는 기회가 있을 수 있습니다. 예를 들어, 개체 탐지에서 최대가 아닌 억제를 적용하여 중복 탐지를 제거할 수 있습니다.
문제 규칙에서 요구하는 대로 제출 중에 외부 데이터와 사전 훈련된 모델의 사용을 표시해야 합니다. 그리고 항상 그렇듯이 데이터와 모델을 이해하고 최적의 접근 방식을 찾기 위해 반복하고 실험하는 것이 핵심입니다.
체크요소 (6/12)
1. Swin-MAE가 어느 정도 Data augmentation에 기여할 수 있는가? << 패스. 그닥 도움 안 될듯.
2. tph-yolov5가 data augmentation을 자기 자신이 실행하는가? << 진행
Feature Map에 CBAM과 Transformer을 적용하는 이유와 그 차이
1) Purpose of CBAM:
Convolutional Block Attention Module (CBAM) is a type of attention mechanism that can be integrated into Convolutional Neural Networks (CNNs). The purpose of CBAM is to provide a way for the model to focus on important features and ignore less important ones. It does this by applying both spatial and channel-wise attention. The spatial attention allows the model to focus on important regions of the input, while the channel-wise attention allows the model to focus on important channels (i.e., feature maps). This can help improve the performance of the model by allowing it to focus on the most relevant information.
2) Why Transformers in Feature:
Transformers are a type of model that also uses attention mechanisms, but they are typically used for sequence-to-sequence tasks like language translation or text generation. However, they can also be applied to feature maps in a CNN. The reason for doing this is that Transformers can model long-range dependencies between features, which can be beneficial for tasks where the spatial relationship between features is important. For example, in object detection, the relationship between different parts of an object can be important for correctly identifying the object.
3) The difference between CBAM and Transformer:
The main difference between CBAM and Transformers is how they apply attention. CBAM applies attention separately to the spatial and channel dimensions of the feature maps, while Transformers apply attention to the flattened feature maps, considering both spatial and channel dimensions at the same time. This means that Transformers can model the relationship between different parts of the feature map more directly, but at the cost of increased computational complexity. On the other hand, CBAM is more computationally efficient, but it may not model the relationships between features as effectively as Transformers.
--- Sure, let's break it down:
1) Purpose of CBAM:
Imagine you're in a crowded room and you're trying to focus on a conversation. You can't pay attention to everything at once, so you focus on the person speaking and ignore the rest. This is similar to what CBAM does. It helps the model to focus on the important parts of an image (like the person speaking in our example) and pay less attention to the less important parts (the background noise).
2) Why Transformers in Feature:
Now, imagine you're trying to put together a jigsaw puzzle. You can't just look at each piece in isolation, you need to understand how they fit together. This is what Transformers do. They help the model understand how different parts of the image relate to each other (like how different pieces of the puzzle fit together).
3) The difference between CBAM and Transformer:
CBAM and Transformers are like different strategies for listening to a conversation in a crowded room. CBAM is like focusing on one person at a time, then switching to another person. On the other hand, Transformers are like trying to listen to everyone at once and understanding the whole conversation. Both strategies have their own strengths and weaknesses. CBAM is simpler and faster, but might miss some details. Transformers are more thorough, but can be slower and more complex.
--- When the CNN feature passes through the Transformer and CBAM, the feature values are modified based on the attention mechanisms of these modules. Here's a simplified explanation of how it works:
1) Transformer:
The Transformer module takes the CNN features and applies a self-attention mechanism. This means that the value of each feature is updated based on its relationships with all other features. For example, if a certain feature (say, a pixel in an image) is strongly related to other features (other pixels), its value will be updated to reflect this strong relationship. This allows the Transformer to capture complex dependencies between features.
2) CBAM:
The CBAM module applies both spatial and channel-wise attention to the CNN features. The spatial attention allows the model to focus on important regions of the image, while the channel-wise attention allows the model to focus on important feature channels. For example, if a certain region of the image (spatial attention) or a certain feature channel (channel-wise attention) is important for the task at hand, the values of the features in this region or channel will be amplified. So, in both cases, the original feature values are updated to reflect the importance of each feature for the task at hand. This importance is determined based on the relationships between features (in the case of the Transformer) and the importance of different regions and channels (in the case of CBAM).
컴퓨터 비전, 특히 객체 감지 작업에서 특징 맵에 트랜스포머를 적용한다는 것은 컨볼루션 신경망(CNN)이 생성한 특징 맵을 처리하기 위해 트랜스포머 아키텍처를 사용한다는 것을 의미합니다.
원래 자연어 처리 작업을 위해 제안된 트랜스포머 모델은 데이터 내의 장거리 글로벌 종속성을 모델링할 수 있기 때문에 시퀀스 데이터를 처리하는 데 큰 성공을 거두었습니다. 특징 맵에 트랜스포머를 적용하면 이미지의 여러 영역 간의 종속성을 모델링하는 데 도움이 될 수 있으며, 이는 이미지의 여러 부분 간의 컨텍스트와 관계를 이해하면 성능을 향상시킬 수 있는 객체 감지와 같은 작업에 유용할 수 있습니다.
다음은 작동 방식에 대한 간단한 설명입니다:
1. CNN에 의해 생성된 특징 맵은 이미지의 각기 다른 영역에 해당하는 일련의 특징 벡터로 재구성되거나 평탄화됩니다.
2. 그런 다음 이 시퀀스를 Transformer에 공급합니다. 트랜스포머는 자체 주의 메커니즘을 사용하여 각 피처 벡터에 대해 이미지의 여러 영역의 중요도를 서로 비교하여 가중치를 매깁니다. 이렇게 하면 각 출력 벡터가 모든 입력 벡터의 가중치 조합이므로 이미지의 전체 컨텍스트를 캡처할 수 있습니다.
3. 그런 다음 트랜스포머의 출력을 다시 2D 공간 차원으로 재구성하여 입력 피처 맵과 동일한 공간 차원을 가지지만 글로벌 컨텍스트 정보가 보강된 새로운 피처 맵을 얻을 수 있습니다.
4. 이 새로운 특징 맵을 물체 감지와 같은 다운스트림 작업에 사용할 수 있습니다.
이 접근법의 장점은 이미지의 여러 부분 간의 복잡한 종속성을 모델링할 수 있다는 점이며, 이는 맥락에서 객체를 감지하는 데 특히 유용할 수 있습니다. 그러나 이미지의 픽셀 수에 따라 4제곱으로 확장되는 계산 복잡성을 갖는 자기 주의 메커니즘으로 인해 계산 집약적일 수도 있습니다.
모델 설계에서의 주의점
특히 작은 물체를 감지하는 YOLO와 같은 모델의 성능을 개선하는 것은 어려울 수 있습니다. 새 모듈을 추가할 때는 아키텍처의 전반적인 일관성과 해결하려는 특정 문제를 고려하는 것이 중요합니다. 다음은 모델을 개선하기 위한 구조화된 접근 방식입니다:
1. **문제 이해하기**:
- 작은 물체 감지**: 작은 물체는 세부적인 특징이 부족하여 감지하기 어려운 경우가 많습니다. 초기 레이어의 고해상도 특징 맵이 도움이 될 수 있습니다. 이러한 초기 특징 맵을 활용하는 연결을 추가하는 것을 고려하세요.
2. **모듈 선택**:
- 주의 메커니즘**: CBAM, 트랜스포머, SimAM과 같은 모듈은 주의 메커니즘입니다. 이러한 모듈은 모델이 관련성이 높은 피처에 집중하고 관련성이 낮은 피처는 억제하도록 도와줍니다. 하지만 무턱대고 추가하는 것이 항상 도움이 되는 것은 아닙니다. 주의 메커니즘이 가장 유용할 수 있는 위치를 고려하세요. 예를 들어, 주의 메커니즘은 모델이 낮은 수준의 특징과 높은 수준의 의미를 조화시키려는 중간 계층에서 더 유용할 수 있습니다.
- 피처 피라미드 네트워크(FPN)**: 다양한 크기의 물체를 감지할 때는 FPN이 유용할 수 있습니다. 멀티 스케일 피처를 결합하여 여러 스케일에서 감지를 개선합니다.
3. **점진적 통합**:
- 한 번에 여러 모듈을 추가하는 대신 한 번에 하나의 모듈을 통합합니다. 이렇게 하면 각 추가의 효과를 모니터링하고 그 영향을 이해할 수 있습니다.
4. **정규화**:
- 모듈을 더 추가하면 모델의 용량이 증가합니다. 이는 특히 데이터가 제한적인 경우 과적합으로 이어질 수 있습니다. 정규화(예: 드롭아웃, 가중치 감쇠)를 늘리거나 데이터 증강과 같은 기법을 사용하는 것이 좋습니다.
5. **훈련 전략**:
- 학습률**: 새 모듈을 추가할 때 이러한 모듈의 초기 가중치가 최적이 아닐 수 있습니다. 학습률 워밍업과 같은 학습률 스케줄을 사용하여 학습을 안정화하는 것이 좋습니다.
- 배치 크기**: 배치 크기가 클수록 더 안정적인 그라데이션을 제공할 수 있습니다. 메모리가 제한적인 경우 그라데이션 누적과 같은 기법이 도움이 될 수 있습니다.
- 손실 함수**: 손실 함수가 목적에 맞는지 확인하세요. 작은 물체를 감지하는 경우 작은 물체에 대한 손실에 더 많은 가중치를 부여할 수 있습니다.
6. **평가**:
- 적절한 지표를 사용하세요. 작은 물체 감지에 초점을 맞추고 있다면 평가 지표에 이러한 초점을 반영해야 합니다.
- 시각화 도구를 사용하여 어떤 물체가 놓치고 있는지 검사하세요. 이를 통해 무엇이 잘못되었는지에 대한 인사이트를 얻을 수 있습니다.
7. **피드백 루프**:
- 변경을 수행한 후에는 유효성 검사 집합으로 돌아가 수정 사항이 처음에 식별한 특정 문제에 도움이 되는지 확인합니다.
8. **연구 및 커뮤니티**:
- 최근 연구 결과를 최신 상태로 유지하세요. 커뮤니티에서 특정 문제를 해결하기 위한 새로운 기술을 제안하는 경우가 종종 있습니다. - 사전 훈련된 모듈을 고려하세요. 때로는 다른 작업에서 학습된 모듈을 모델에 통합하여 미세 조정할 수 있습니다.
9. **제거 연구**:
- 몇 가지 변경을 수행한 후에는 제거 연구를 수행합니다. 여기에는 한 번에 하나의 변경 사항을 제거하고 그 영향을 측정하는 것이 포함됩니다. 이를 통해 각 수정 사항의 기여도를 이해하는 데 도움이 될 수 있습니다.
10. **반복**:
- 모델 개발은 반복적입니다. 평가에 따라 돌아가서 접근 방식을 개선하고 다시 시도하세요.
성능을 개선하기 위해 더 많은 모듈을 추가하고 싶은 유혹이 있지만, 근본적인 문제를 이해하고 체계적으로 해결하는 것도 마찬가지로 중요하다는 점을 기억하세요. 때로는 더 나은 데이터 전처리 또는 다른 학습 속도 일정과 같은 간단한 변경만으로도 상당한 개선 효과를 얻을 수 있습니다.
실험 세팅에서 주요사항
연구 논문, 특히 딥 러닝과 컴퓨터 비전에서 보고된 성능은 엄격한 실험과 평가에 이상적으로 기초한다. 그러나 이러한 결과의 실제 적용 가능성과 재현성은 몇 가지 이유로 인해 실제로 달라질 수 있다. 다음은 요인과 고려 사항을 분류한 것이다:
1. **실험 설정**:
- 저자들은 일반적으로 데이터 전처리, 데이터 증강(모자이크와 같은), 훈련 전략, 하이퍼 파라미터 및 평가 메트릭을 포함하여 실험 설정에 대해 자세히 설명한다. 이 설정은 다른 사람들이 결과를 재생산할 수 있도록 하기 위한 것이다.
2. **임의성**:
- 딥 러닝은 많은 무작위성의 원천을 포함한다: 가중치의 초기화, 데이터 셔플링, 드롭아웃 계층 등. 동일한 코드와 데이터가 있더라도 두 번의 실행은 약간 다른 결과를 생성할 수 있다. 이를 설명하기 위해 연구자들은 종종 여러 실행에 대한 평균 성능을 보고하거나 고정 무작위 시드를 사용한다 (비록 후자가 다른 플랫폼 또는 소프트웨어 버전에서 항상 재현성을 보장하는 것은 아니지만).
3. **다중 데이터셋에 대한 평가**:
- 모델의 견고성을 입증하기 위해 연구자들은 종종 여러 데이터 세트에서 모델을 평가한다. 다양한 데이터 세트에서 잘 수행되는 모델은 실제 시나리오에서 더 강력할 가능성이 있다.
4. **Ablation Studies**:
- 각 성분 또는 수정의 기여도를 이해하기 위해 연구자들은 절제 연구를 수행한다. 이는 모델 또는 훈련 과정의 특정 부분을 제거 또는 변경하고 성능에 미치는 영향을 관찰하는 것을 포함한다.
5. **기준과 비교**:
- 좋은 논문들은 동일한 조건에서 제안된 방법을 기존의 기준 방법과 비교한다. 이는 보고된 성능에 대한 맥락을 제공한다.
6. **벤치마크에 과적합**:
- 연구계에서는 모델이 벤치마크에 "과적합"되는 것에 대한 우려가 있다. 많은 모델이 특정 데이터 세트에 대해 특별히 훈련되고 조정된다면, 그들은 해당 데이터 세트에서는 예외적으로 잘 수행되지 않을 수 있지만 실제 다양한 시나리오에서는 수행되지 않을 수 있다.
7. **복제성 문제**:
- 모든 논문이 코드를 제공하는 것은 아니며, 코드를 제공하는 경우에도 재현성에 영향을 미칠 수 있는 뉘앙스나 문서화되지 않은 단계가 있을 수 있다. ML 커뮤니티는 코드, 데이터 및 세부 실험 설정 공유를 포함하여 더 나은 재현성 표준을 추진하고 있다.
8. **실제 변동성**:
- 벤치마크된 데이터셋은 실제 데이터보다 깨끗하고 균형이 잡힌 경우가 많다. 실제에서는 데이터가 더 지저분하고 더 불균형하며 벤치마크 데이터셋에는 없는 문제가 있을 수 있다.
결론적으로, 논문의 성능 지표가 가치 있는 통찰력을 제공하지만, 항상 모든 실제 시나리오에 직접적으로 번역될 수 있는 것은 아니다. 더 넓은 맥락을 고려하고, 실험 설정을 이해하며, 가능하면 실제 조건이나 새로운 데이터 세트에서 모델을 테스트하여 실제 효과를 측정하는 것이 필수적이다.
평가할 성능들은 아래와 같다.
| Yolov5 | 0.37739 | 468 layers, 46186759 param, 108.4 GFLOPs |
| Yolov5 + TPH | 0.38474 / 0.41243(tphxs) | |
| Yolov5 + 내거 | 0.38766 / 0.419(tphxs) | |
| Yolov7 | 0.4177 | 415 layer, 37245102 param, 105.3 GFLOPS |
| Yolov7 + TPH | 0.3913 | |
| Yolov7 + 내거 | 0.393 |
1) RepConv + (C)Swin --> 폐기
2) RepGhost --> 폐기
3) RepConv + C3(C)STR
4) MP 이후, 또는 ELAN 이후에 Transformer 부착
분석 논문으로 진행할 시
Head 별로 다른 Transformer을 삽입하면서 성능 분석 & 가능하다면 (내가 고안한) 추가 모듈을 넣어서 성능 증가 노려보기
관건은 왜 Transformer로 Head를 교체하면 성능이 증가하는가? 이것의 분석이 꽤나 중요할 것.
1) Improved YOLOv7 for Small Object Detection Algorithm Based on Attention and Dynamic Convolution


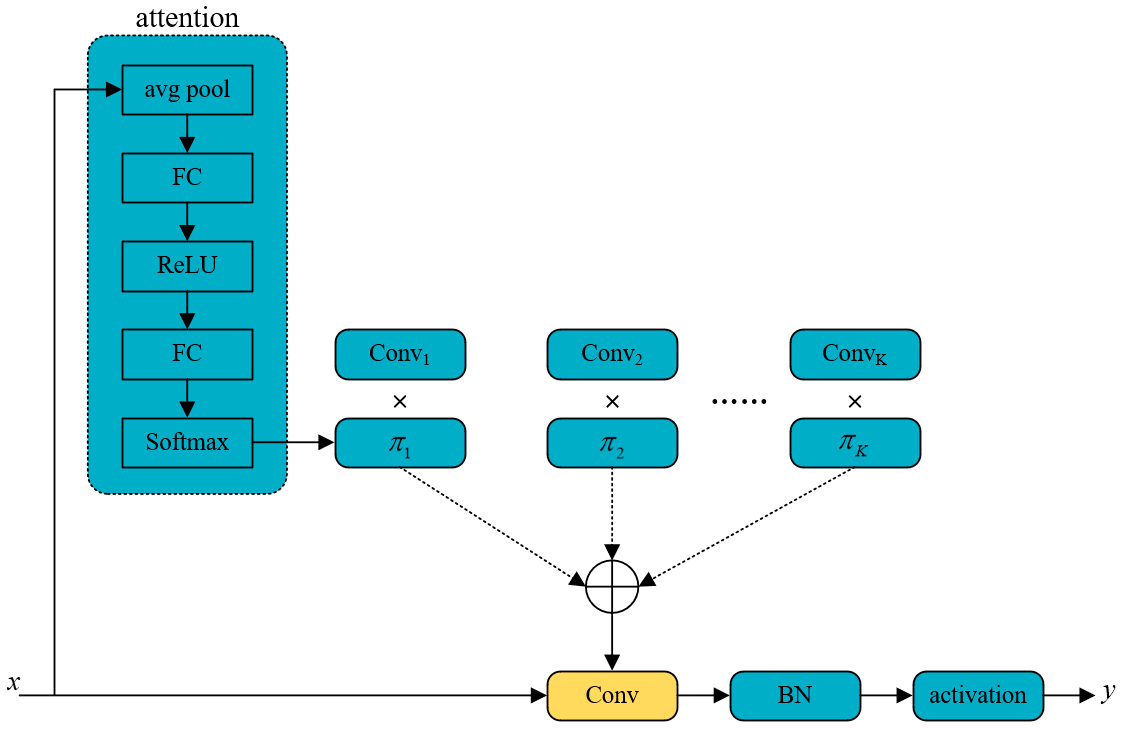
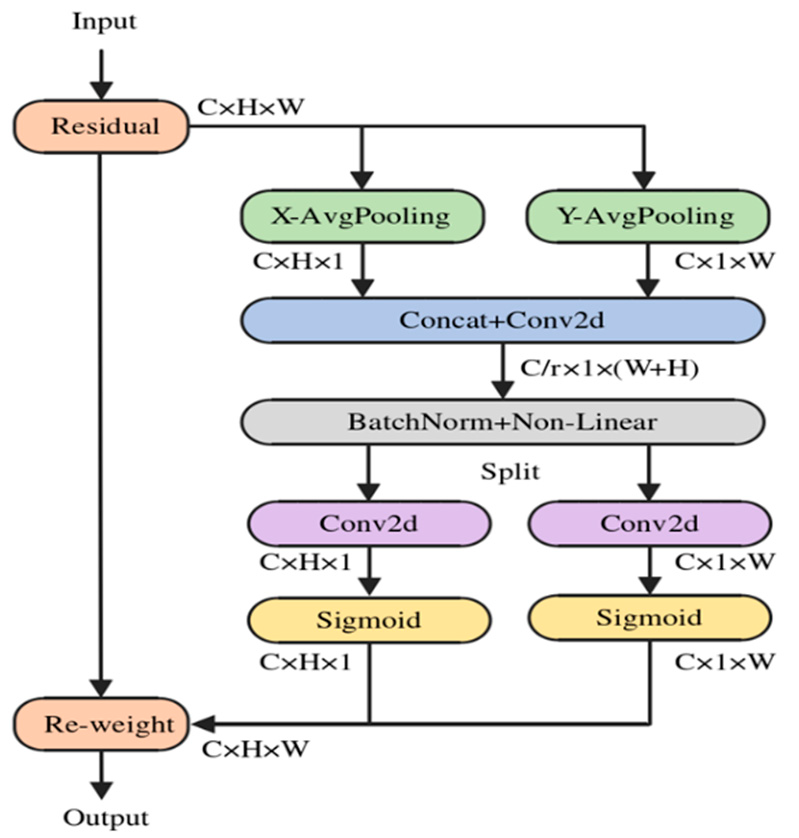
2) Improving YOLOv7-Tiny for Infrared and Visible Light Image Object Detection on Drones

3) MS-YOLOv7:YOLOv7 Based on Multi-Scale for Object Detection on UAV Aerial Photography

4) Small-Object Detection for UAV-Based Images Using a Distance Metric Method
5) TPH-YOLOv5: Improved YOLOv5 Based on Transformer Prediction Head for Object Detection on Drone-captured Scenarios
6) YOLOv7-sea: Object Detection of Maritime UAV Images based on Improved YOLOv7
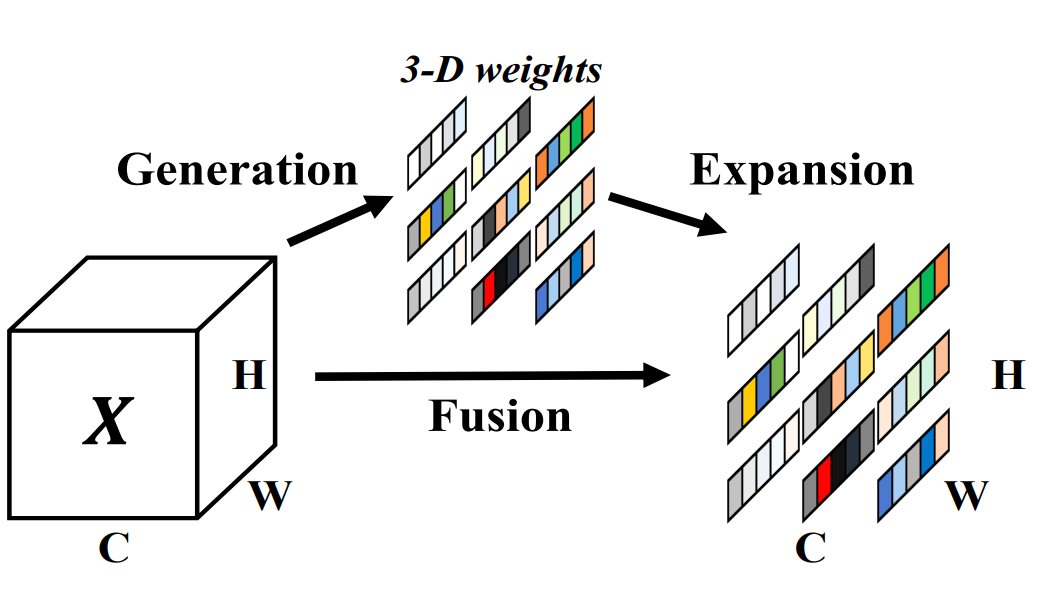
제안 그림
5x5에서 중앙기준 (1,5) (5,1)
7x7에서 중앙기준 (3,7)(7,3)
9x9에서 중앙기준 (9,5) (5,9)
'Legacy > 과거 프로젝트 공부용' 카테고리의 다른 글
| [딥러닝 정보] EMA & 차세대 모델 (0) | 2023.10.13 |
|---|---|
| [확통] 2 (0) | 2023.06.12 |
| [Optical flow] GradScale (0) | 2023.06.04 |
| CLTR 분석 (0) | 2023.02.22 |
| 마르코프 체인 / 몬테카를로 예측 / 선형 칼만 필터 (0) | 2023.02.19 |

