실제 코드 https://jwgdkmj.tistory.com/216
GAN의 G와 D 객체
전체코드 https://github.com/jwgdmkj/jupiterColab/blob/master/GANProduction_1213.ipynb 전처리 #Gan With Pytorch import torch import torchvision import torch.nn as nn import torch.nn.functional as F f..
jwgdkmj.tistory.com
참조 https://taeyoung96.github.io/cs231n/CS231n_13/
CS231n 13강 요약
Unsupervised Learning과 Generative Models에 대해서 알아보자!
taeyoung96.github.io
https://memesoo99.tistory.com/42?category=955851
cs231n - 13강 - Generative Models
*본 글은 cs231n 13강의 내용을 정리 요악한 글입니다. 오늘은 비지도 학습의 대표격인 생성모델에 대해 알아보겠습니다. Supervised Learning vs. Unsupervised Learning Supervised 일명 지도학습은, 학습데이터..
memesoo99.tistory.com

비지도학습이란, 클러스터링 or 차원축소처럼 데이터의 숨어있는 기본적인 구조를 학습하는 것을 목표로 학습하는 방법.
즉, 정답이 뭔진 알바 아니고, label도 없고, 그냥 그 구조를 보고 '아 이건 정답이거겠네'하고 판단하는 법.
따라서, 일일이 data에 label을 붙일 필요가 없으니 cost는 적으나, 인간은 그 기준을 명확히 알기 어렵다는 단점이 있다.
생성모델이란, Training Data를 넣어줬을 떄, 그와 비슷한 분포를 갖는 new data를 생성하는 모델. GAN을 생각해보라.

즉, 생성모델은 비지도학습의 일부가 될 것이다. 이 생성모델은 분포추정(Density Estimation)이 아주 중요하다.
- Explicit Density Estimation : 생성 모델 를 명시적으로 나타내주는, 어떤 분포를 띄는지 찾는 방법
- Implicit Density Estimation : 생성 모델 를 정의하지 않고, 단순 Sample을 생성할 수 있는 수준을 원함
각각을 비교하면 아래와 같다.
Explicit density: Training data의 likelihood를 높이는 방향으로 학습하려 한다. x1_xi까지가 각 pixel이 등장할 확률이라면, 해당 pixel들로 구성된 이미지가 나타날 확률은 각 pixel들의 확률곱이 될 것이다. 따라서 아래와 같은 식으로 나타낼 수 있다. 여기에 더불어 Loss도 계산할 수 있어서 학습 정도를 알 수 있다.
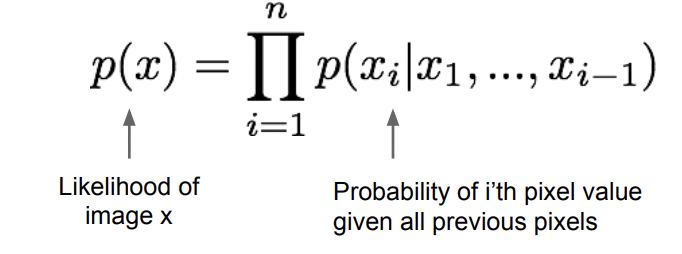
위의 식을 보면 알 수 있듯, x1~xi-1이 나올 때 xi가 나올 확률을, i=1부터 n까지 전부 곱한 것으로 정의함을 알 수 있다.
그러나 데이터가 복잡해질수록 분포를 식으로 표현해 계산하기 어렵고, 그렇기에 모델을 정의하는 데에 한계가 있어, loss를 계산할 수 있단 장점에도 불구하고 implicit을 택한다.
아무튼 그래서 p(x)는 알았는데, 그것을 구성하는 픽셀 각각(xi)은 어떻게 정의되는가?
그 픽셀들을 정의하는 데 쓰이는 것이 Pixel Rnn이란다.
뭔고 하니, LSTM을 이용해 모델링을 하여, 인접한 픽셀을 이용해 순차적으로 픽셀을 생성한단다.
뭔소린가..

그림을 보면 알 수 있듯, 왼쪽 위 코너의 시작점으로부터 상하좌우로 뻗어가면서, 이미지를 pixel by pixel로 생성한다.
즉, 이전 픽셀에 대한 dependency가 있기에, LSTM같은 RNN으로 구현되는 것.
하지만 순차적으로 픽셀들을 생성하기 때문에 굉장히 속도가 느리다는 것이 단점이다.
이러한 단점을 보완하기 위해 나온 방법이 PixelCNN이다.

이미지 생성에 영향을 주는 인접한 좌표들에 한꺼번에 CNN을 하는 방식. RNN 대신 CNN을 이용하여 픽셀을 생성한다.
CNN을 이용하면 특정 영역만 사용하기 때문에 훨씬 더 빠르게 이미지를 생성할 수 있고, 병렬적으로 Training도 가능하다.
PixelRNN과 PixelCNN 모두 Training은 Training Image에 대해 Likelihood를 최대로 하도록 training을 시킨다.
Likelihood란 확률 분포의 모수가, 어떤 확률변수의 표집값과 일관되는 정도를 나타내는 값이다.
앞서 살펴본 PixelCNN 같은 경우 확률 모델이 계산 가능한 함수(p(x))로 정의가 되었다.
하지만 VAE(Variational Autoencoders)는 확률 모델이 계산 불가능한 함수로 정의가 된다.
따라서 Lower bound(하한선)를 구해서 계산 가능한 형태로 만들어줘야 한다.

아니, 갑자기 VAE(Variational Autoencoders)가 뭔데?
그 전에 Autoencoder의 과정, Encoder와 Decoder가 무엇인지 한 번 알아보자.
Autoencoder : Deep Neural network를 이용하여 데이터의 추상화를 위해 사용한다.
기존의 차원축소 문제들은 Unsupervised Learning(비지도학습)이었는데, 이를 encoder와 decoder로 이루어져있는 NN를 이용하여 supervised Learning(지도학습)문제로 바꾸어서 해결하는 것으로,
데이터를 압축해서 다시 복원을 할 때, Training Data에 근거해서 복원하는 방식으로 차원 축소를 하는 방식이 곧 AutoEncoder이다.
encode : 입력이 특정한 형태로 변환하는 것. 인공신경망이 학습하기 위해서는 문자보다는 숫자가 에러를 계산하기에 적합하기에 쓰인다.
decoder : (encoder가 만든 것을) 원래의 형식으로 복원하는 역할을 한다. 예를들어 숫자를 넣으면 문자로 변환해주는 것처럼 말이다.
autoencoder : 입력과 출력을 같도록하는 구조를 말한다. 노이즈 제거에 탁월하며, unsupervsied learning 방법 중 하나이다. 입력값에 특별히 label 혹은 정답 데이터가 따로 있는 것이 아니라, 입력값 그 자체가 정답이 되므로 supervised되는 것이 없다. 따라서 unsupervsied 이지만, 좀 더 엄밀히 말하자면 self-supervised learning이다. 입력값이 정답이 되므로, 스스로 답을 주는 self-supervised라고 할 수 있다.
일반적 구조는 input -> encoder -> decoder -> output이다.
그림 1) ref: https://excelsior-cjh.tistory.com/187
헌데 여기서 Auto Encoder은, input에 최대한 똑같게 output이 나오도록 한다. 이게 도대체 무슨 의미가 있냐?
자세히 들여다보면, input과 output의 개수와 중간에 hidden layer의 노드의 개수가 다르다. 그렇다는 것은, hidden layer에서 차원이 축소가 되었고, output이 input을 충분히 잘 표현한다면 그 축소는 매우 의미있는 축소가 될 것이다.
또한 입력 데이터에 노이즈를 더해 입력하여 인코딩하고, 디코더를 통해서는 노이즈가 없었던 원본 데이터를 복원하도록 하는 문제를 설계할 수도 있다. 이러한 문제설정을 통해서 단순히 input을 output으로 뱉어놓는 것이 아니라, input을 output으로 변환하기 위해서 표현(representation)하는 중간 상태를 잘 만드는 것이 목표이다.
그런데 이러한 표현을 잘 하도록 학습하기 위해서는 문제(loss)를 잘 설계해야한다. 단순히 입력이 출력으로 나오는 문제를 조금 변형하여야 하는데, 일반적으로는 퍼즐 맞추기, 노이즈 제거, 해상도 매칭 등이 있다.
그림 2) ref: Unsupervised Learning of Visual Representations by Solving Jigsaw Puzzles
이러한 오토인코더가 갖는 의미는 다음과 같다.
1. 모델이 데이터를 바라보는, 이해하는 시각/표현을 latent vector를 통해 얻을 수 있다.
일반적으로 인코더는 차원을 축소하기 때문에, 입력받는 것을 '문제를 해결하기 위한 어떠한 벡터'로 변환시킨다.
결국 풀고자 하는 문제는 입력값을 출력값으로 되돌리는 것이기 때문에, 그 벡터는 입력값에 대한 정보를 최대한 압축하듯이 잘 담아낸다. 이러한 값은 representation, (latent) feature, embedding 등의 용어로 혼용된다. latent vector를 잘 생성하고 활용하는 것은 이후에 이 정보를 이용해 어떠한 작업을 하는지에 영향을 미치기 때문에 마치 데이터를 가공하는 전처리과정처럼 매우 중요하다.
2. 오토인코더에서 decoder 부분은 특정한 vector로부터 학습된 형태로 변환(복원)하는 기능을 갖는다.
일반적으로 autoencoder는 encoder와 decoder가 대칭적인 구조를 갖는다. 위에서 생성/추출한 latent vector를 이용해 원하는 결과 이미지를 생성해낼 수 있다. 이러한 '생성'의 측면으로 보았을때, decoder는 generator가 될 수 있는 것이다. 대표적인 generative 모델로는 GAN이 있지만, VAE도 있다.
autoencoder는 linear autoencoder, 각 단계의 weight를 초기화하는 Stacking Autoencoder, 학습 데이터에 노이즈를 추가한 Denoising AutoEncoder(DAE), regularizer를 추가한(=noise 역할) Stochastic Contractive Autoencoder(SCAE), 테일러 전개를 이용해서 stochastic을 deterministic하게 바꾼 Contractive Autoencoder(CAE), latent variable을 찾고자 만들어진 Variational Autoencoder(VAE)
결론
1) Auto Encoder은 입력값을 받으면 이를 최대한 출력값에 가깝게 내보낸다.
2) 그 사이의 Hidden Layer는 Input과 Output보다 노드가 적다.
3) 따라서, 이 인코더의 역할은 "보다 더 적은 정보량으로 Input을 만들어내는, 일종의 데이터 축소" 역할을 같게 된다.
4) 이러한 축소 및 원본유지를 통해 Noise 제거 등과 같은 것부터, 학습을 통해 GAN처럼 일종의 이미지 생성기(Generator)로서의 역할도 해낼 수 있다.
https://lv99.tistory.com/22


Encoder란 Input data X가 들어왔을 때, 그 특징 벡터 z를 추출하는 과정을 말한다.
Encoduer의 예로는 Sigmoid, Fully Connected Layer, ReLU, CNN 등이 있다.
특징 벡터 z는 보통 Input data X보다 작다. 즉, 차원이 줄어든 형태이다.
이를 통해, Input Data에서 Noise 등을 제거하고, 중요한 특징만 담은 특징벡터를 이용해 z를 구성하기 위함이다(위의 오토인코더의 결론과 비슷한 맥락)
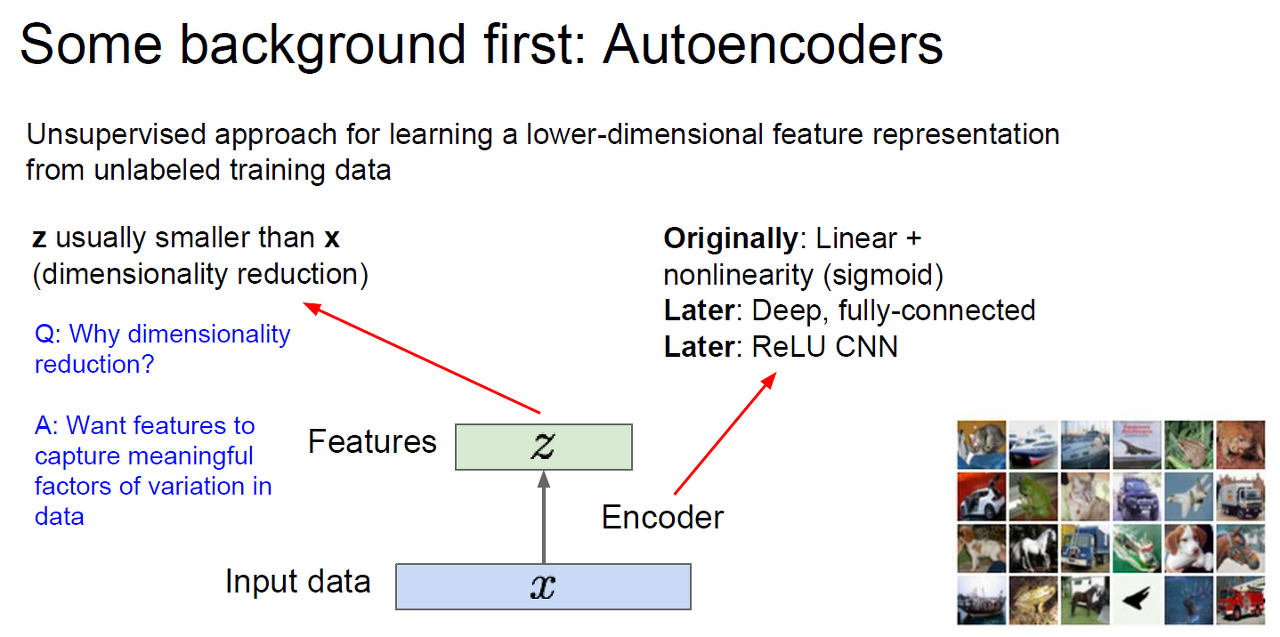
위에서 써두었듯, Feature Representation을 학습한다고 했다. 이는 원본을 다시 복원(reconstruct)하는데 사용할 수 있는 특징들을 학습하는 방식을 취한다. 이 때, 복원된 이미지와 원본 이미지의 차이를 계산하기 위해서 L2 loss function을 쓴다.

Auto-Encoder는 우선 z를 생성하고, 다음으로 x_hat을 생성해서 최종적으로 와 x_hat의 차이를 최대한 줄이도록 feature z를 학습한다.
Decoder는 training할 때만 쓰이고, 실제로 test를 할 때는 Encoder만 가지고 진행한다. Decoder은 오직 z를 학습하는데 있어 input x와 비교할 기준이 필요하기에, 그 기준인 x_hat을 만드는데만 쓰인다.
Encoder는 초기에 supervised learning에 의해 초기화 된 모델의 초기값을 이용한다.
즉 기존의 Unsupervised learning였던 것을 self-supervised learning 문제로 풀 수 있도록 바꾼 것이 AutoEncoder라고 할 수 있다. (사실 용어 상에 큰 차이는 없다. https://sanghyu.tistory.com/184#:~:text=Self%2Dsupervised%20learning%20%EC%9D%B4%EB%9E%80%3F,representation%20learning%EC%9D%98%20%EC%9D%BC%EC%A2%85%EC%9D%B4%EB%8B%A4. 참조.)
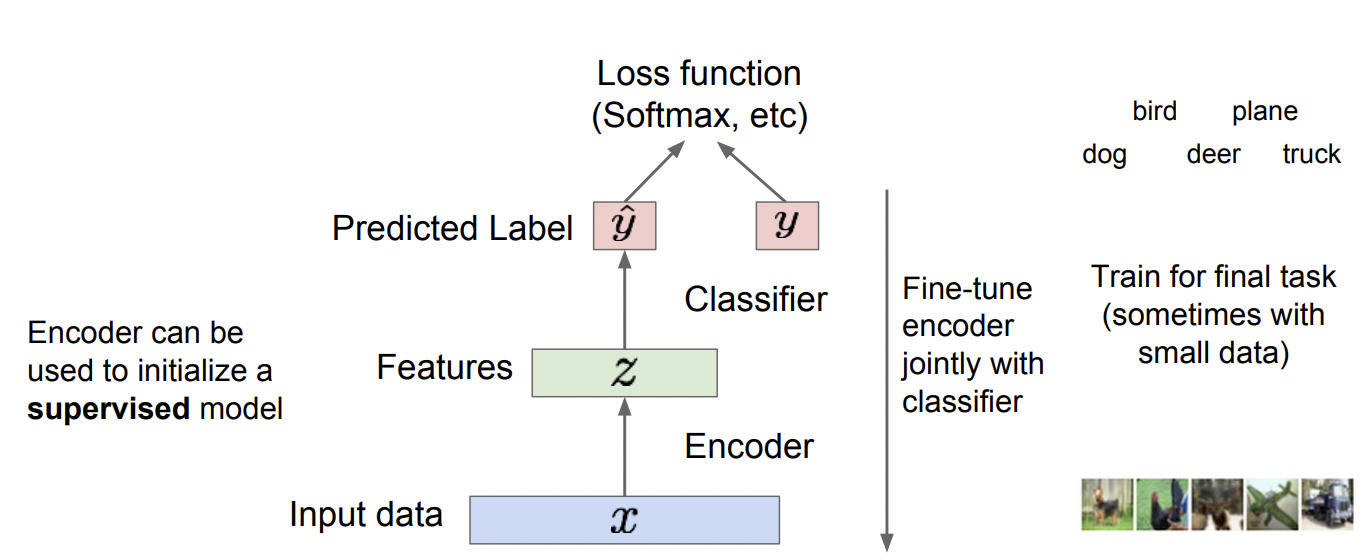
Decoder를 제거한 모델은 feature만 남게 되며, 이 feature은 적절한 학습을 통해 input data x의 중요한 feature을 추출해낼 수 있게 되었다. 이 feature을 data의 특성을 잘 반영하게끔 추출하는 것이 Auto Encoder의 목적이다.
이 feature는 supervised model의 input으로 들어가, classification 하는데 사용한다.
data가 넉넉하지 않을때, overfit/underfit되는걸 최대한 줄이기 위해 이런 복잡한 과정을 거친다.
VAE(Variational Autoencoders)는 AutoEncoder가 중요한 특징 벡터들을 잘 추출하고 있는데, 이러한 벡터들을 이용하여 이미지를 재구성할 수는 없을까라는 아이디어에서 나온 방법이다.
먼저 학습 데이터가 있는데, 이 데이터가 관측할 수 없는 잠재 변수(특징 벡터) z에 대해서 재구성 되는 것이라 가정하자.
z는 다양한 종류의 특성들을 담고 있는데, 예를 들어 얼굴을 생성할 때 특성을 담고 있다고 하면, 입꼬리가 올라갔는지, 눈썹의 방향, 머리 스타일 등을 담고 있다고 생각하면 된다.
강의에서 prior라는 용어가 자주 나오는데, 이는 확률 분포 관점에서 어떠한 event가 일어날 지에 대한 기대값이라고 한다.
보통 prior를 선택할 때 가우시안 분포를 사용하여 표현한다.

생성 모델을 잘 만들기 위해서는 의 파라미터 값들을 잘 추정해야 하는데,
여기서 나온 파라미터는 1) Prior Distribution, 2) Conditional Distribution 2가지가 있다.
Prior distribution의 같은 경우, 기댓값의 분포이므로 가우시안 함수로 간단하게 표현하지만,
Conditional distribution(조건부 분포)와 같은 복잡한 함수의 경우 Neural Network를 이용하여 표현한다.
그렇다면 VAE model은 어떻게 training을 시킬까? 우선 를 정의한다.

z - latent vector. 상술함.
pθ(z) - parameter가 θ일 때, z를 sampling할 수 있는 확률밀도 함수
pθ(x|z) - parameter가 θ이면서, z가 주어졌을 때 x를 생성해내는 확률밀도 함수.
여기서 를 실제 분포와 가깝게 찾는것이 목표다. 따라서 p(z)에서 p(x|z)를 만드는 Decoder network를 복잡한 구조도 핸들링 가능한 neural network로 구성을 하고, 아래와 같은
- paremeter가 일때 x가 나올 likelihood를 최대화 시키는 방향으로 학습을 한다.
근데 해당 VAE파트 처음에 서술했듯, 는 계산이 불가능한 녀석이다. 왜 계산이 불가능하냐?
가 모든 z(특징벡터)에 대해서 알아내야 를 구할 수 있는데 모든 z는 우리가 알아낼 수 없는 녀석이기 때문이다!
앞서 말한 Explicit Density에서의 경우, 앞서 쓴 모든 픽셀의 조건부확률을 통해 계산이 가능했지만.
이것의 경우, 구하고자 하는 z는 특정 Input을 Output으로 흘려보낼 때 중요한 부분만을 담고 있어 Output으로 그대로 흘러들어갈 특징벡터(입꼬리가 올라갔는지, 앞머리 등등..)이기 때문에, 컴퓨터는 그래서 대체 이것이 무엇인지 계산이 불가능하다(심지어 인간도 모를지도 모른다)!
따라서 추가적인 encoder를 통해서 학습을 시키는데 를 근사한 를 이용한다. 당연히 이 때 는 계산 가능한 녀석이여야 한다.
이때 VAE의 encoder와 decoder는 AE(AutoEncoder)와 유사한 구조이지만 여기에 확률론적 의미가 추가된다.
Encoder와 Decoder에 대한 Network는 다음과 같다.
qϕ(z|x)를 추가하였다.
왼쪽은 인코더, 오른쪽은 디코더 네트워크이다.

Encoder
- Encoder x를 input으로 받아서 mean,covariance추출 후, z space상에서 분포를 생성.
- z는 gaussian 분포를 따른다고 가정.(예시일뿐, 다른 분포도 가능)
Decoder
- gaussian 분포로부터 z를 sampling.
- sampling한 z를 가지고 decoder 는 x space 상의 확률분포를 생성하고, x를 이 분포로부터 sampling
이러한 Encoder-Decoder x - z - z 구조를 갖기에 Auto-Encoder라 할 수 있고, 결과적으로 유의미한 Feature Vector z의 획득이 가능하다(이미지2 참고).
이제 Data likelihood 관점으로 다시 돌아오면,

다음과 같은 식들을 볼 수 있다..
에 대한 식을 나타냈는데, 기댓값으로 표현하고 log의 성질에 의해 다음과 같은 3항으로 나눌 수 있다.
여기서 문제가 되는 항이 바로 3번째 항인데 그 이유는 계산이 불가능하기 때문이다.
하지만 정의에 의해 3번째 항은 0보다 크므로 다음 슬라이드와 같이 바꾸어 줄 수 있다.

따라서 앞에 2항을 가지고 Training을 진행하자.
Training의 과정은 다음과 같다.

Test를 할 때는 Decoder network를 이용하여 test를 한다.

서로 독립되어 있는 잠재 변수 z를 통해서 여러가지 이미지들을 생성할 수 있다.
하지만 생성된 이미지들이 blur한 특징을 갖는 단점이 있다.

VAE는 계산할 수 없는 형태의 확률 분포를 이용하여 계산 할 수 있는 형태로 근사 시켜 모델을 만든다는 특징이 있다.
하지만 직접 최적화를 진행하는 PixelRNN/CNN보다 만들어진 이미지의 Quality가 떨어진다는 단점이 있다.
GAN(Generative Adversarial Networks)Permalink
GAN은 앞서 살펴본 방법들과는 달리 확률 분포를 계산하는 것을 포기하고 단지 Sample을 얻어내는 방법을 말한다.
즉, 결과만 뽑아내는 것이다.
GAN을 구현하기 위해서는 "G(Generator Network)"와 "D(Discriminator Network)" 두 가지의 Network가 필요하다.
Generator Network는 Discriminator를 속여 실제처럼 보이는 가짜 이미지를 만들어 내는 것이 목적이다.
Discriminator Network는 진짜 이미지와 가짜 이미지를 구별해 내는 것이 목적이다.

GAN의 objective funtion은 다음과 같다.

Discriminator network와 Generator Network를 번갈아 가면서 학습을 진행한다.

실제로는 Generator Network의 학습이 제대로 이루어지지 않는 것을 확인할 수 있는데, Gradient의 정도가 오차가 심할 때 크지 않기 때문이다.
즉, Loss값이 큰 경우 기울기 값이 크게 되어 update가 매끄럽게 진행되어야 하는데,
그 반대로 Loss값이 작은 경우 기울기 값이 크기 때문에 약간의 Trick을 이용하여 Objective Function을 바꾸어준다.

다른 Network들이 Training을 할 때 batchsize를 정해주듯이,
여기서는 k의 값으로 한 번에 training을 할 양을 정해준다.
Training을 완료한 후, Test를 할 때는 Generator Network를 이용하여 Test를 진행한다.

GAN을 통해 만든 결과물이다.
GAN을 이용한 연구는 정말 무궁무진하게 쏟아지고 있는데,
그 중 하나가 CNN과 GAN을 결합하는 방법이다.
이 방법은 DCGAN이라고 부른다.


이 방법을 이용하면 그냥 GAN을 이용한 것 보다 훨씬 더 진짜같은 이미지들을 많이 만들어 낼 수 있다.

또 다른 방법으로는 해석 가능한 벡터들을 가지고 연산을 수행하여 새로운 이미지를 만들어 내는 방법이다.

GAN에 대해서는 해당 글 맨 위의 코드를 참조하자.
'버츄얼유튜버' 카테고리의 다른 글
| Vision Transformer(22.03.03 재포스팅) (0) | 2022.09.08 |
|---|---|
| Attention과 Transformer (0) | 2022.08.31 |
| Visualizing and Understanding (0) | 2022.08.10 |
| Detection & Segmentation (0) | 2022.08.01 |
| RNN & LSTM (0) | 2022.07.30 |



