가장 중요한 Backbone생성 함수는 아래와 같음
def create_backbone(cfg, use_deform=False,
context=None, default_filter=False):
"""Creates backbone """
in_channels = cfg['in_channel'] # 256
if cfg['name'] == 'Resnet50': # 이걸 진행. ResnotModel50을 pretrain=True 형태로 불러온다.
feat_ext = models.resnet50(pretrained=cfg['pretrain']) # feat_ext = models.resnet50(True)
if len(cfg['return_layers']) == 3:
in_channels_list = [
in_channels * 2,
in_channels * 4,
in_channels * 8,
]
elif len(cfg['return_layers']) == 4: # 이걸 진행
in_channels_list = [
in_channels,
in_channels * 2,
in_channels * 4,
in_channels * 8,
]
else:
raise ValueError("Not yet ready for 5FPN")
elif cfg['name'] == 'Resnet152':
feat_ext = models.resnet152(pretrained=cfg['pretrain'])
in_channels_list = [
in_channels,
in_channels * 2,
in_channels * 4,
in_channels * 8,
]
elif cfg['name'] == 'mobilenet0.25':
feat_ext = MobileNetV1()
in_channels_list = [
in_channels * 2,
in_channels * 4,
in_channels * 8,
]
if cfg['pretrain']:
checkpoint = torch.load("./Weights/mobilenetV1X0.25_pretrain.tar",
map_location=torch.device('cpu'))
new_state_dict = OrderedDict()
for k, v in checkpoint['state_dict'].items():
name = k[7:] # remove module.
new_state_dict[name] = v
# load params
feat_ext.load_state_dict(new_state_dict)
else:
raise ValueError("Unsupported backbone")
print(feat_ext)
out_channels = cfg['out_channel']
backbone_with_fpn = BackBoneWithFPN(feat_ext, cfg['return_layers'],
in_channels_list,
out_channels,
context_module=context,
use_deform=use_deform,
default_filter=default_filter)
return backbone_with_fpn해당 코드는 resnet50을 쓰고 있으며, 따라서
feat_ext = models.resnet(pretrained=cfg['pretrain'])만을 체크해보자.
이 모델의 구조가 어떤지 알기 위해서는
print(feat_ext)를 찍어보면 됨.
그러면 아래와 같다.
ResNet(
(conv1): Conv2d(3, 64, kernel_size=(7, 7), stride=(2, 2), padding=(3, 3), bias=False)
(bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(maxpool): MaxPool2d(kernel_size=3, stride=2, padding=1, dilation=1, ceil_mode=False)
(layer1): Sequential(
(0): Bottleneck(
(conv1): Conv2d(64, 64, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(64, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(downsample): Sequential(
(0): Conv2d(64, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(1): Bottleneck(
(conv1): Conv2d(256, 64, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(64, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
)
(2): Bottleneck(
(conv1): Conv2d(256, 64, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(64, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
)
)
(layer2): Sequential(
(0): Bottleneck(
(conv1): Conv2d(256, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(128, 128, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(128, 512, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(downsample): Sequential(
(0): Conv2d(256, 512, kernel_size=(1, 1), stride=(2, 2), bias=False)
(1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(1): Bottleneck(
(conv1): Conv2d(512, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(128, 512, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
)
(2): Bottleneck(
(conv1): Conv2d(512, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(128, 512, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
)
(3): Bottleneck(
(conv1): Conv2d(512, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(128, 512, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
)
)
(layer3): Sequential(
(0): Bottleneck(
(conv1): Conv2d(512, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(downsample): Sequential(
(0): Conv2d(512, 1024, kernel_size=(1, 1), stride=(2, 2), bias=False)
(1): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(1): Bottleneck(
(conv1): Conv2d(1024, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
)
(2): Bottleneck(
(conv1): Conv2d(1024, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
)
(3): Bottleneck(
(conv1): Conv2d(1024, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
)
(4): Bottleneck(
(conv1): Conv2d(1024, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
)
(5): Bottleneck(
(conv1): Conv2d(1024, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
)
)
(layer4): Sequential(
(0): Bottleneck(
(conv1): Conv2d(1024, 512, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(512, 512, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(512, 2048, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(2048, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(downsample): Sequential(
(0): Conv2d(1024, 2048, kernel_size=(1, 1), stride=(2, 2), bias=False)
(1): BatchNorm2d(2048, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(1): Bottleneck(
(conv1): Conv2d(2048, 512, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(512, 2048, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(2048, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
)
(2): Bottleneck(
(conv1): Conv2d(2048, 512, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(512, 2048, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(2048, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
)
)
(avgpool): AdaptiveAvgPool2d(output_size=(1, 1))
(fc): Linear(in_features=2048, out_features=1000, bias=True)
)가장 먼저 BottleNeck 구조가 나옴.
BottleNeck 구조는 아래와 같음.
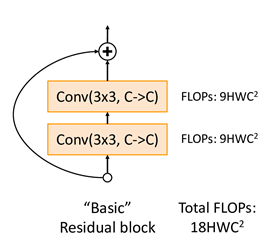
기존의 Residual block은 한 block에 Convolution layer(3x3)을 2개 가진 구조. 그러면 (3x3)x2 = 18번 연산임.

근데 위처럼 바꾸면? layer의 수는 더 많아졌지만, computational cost가 줄어들게 된다.
1x1 convolution 이면 사실 convolution의 의미는 사라지는 것 같다. 영상처리의 개념에서의 filter는 1x1 사이즈라서 의미가 없어지니까(매우 단순한 projection의 의미는 있겠지만..). 하지만, 딥러닝에서 1x1 convolution 을 사용할 때가 있다.
그것은 바로 filter의 수를 조절하는 것이다. 1x1 convolution 이라고만 말하지 않고, filter 수(차원의 수, 채널의 수와 혼용된다.)라는 것이 함께 말해야 의미가 있다.
사실, 입력하는 채널의 수와 출력하는 채널의 수가 완전히 동일하다면 convolution의 큰 의미는 없을 것으로 생각된다. 하지만 차원의 수를 바꿔준다면! 이야기는 달라진다. 차원을 크게도, 그리고 작게도 만든다. 입력받는 것에 비해 적은 수의 차원으로 채널의 수로, filter의 수로 만들어 준다면- 차원이 축소된 정보로 연산량을 크게 줄일 수 있다. 한번 이렇게 줄여 놓으면 뒤로가면 연계되는 연산량의 수, 파라미터의 수가 확 줄어들기 때문에 같은 컴퓨팅 자원과 시간 자원으로 더 깊은 네트워크를 설계하고 학습할 수 있게 된다. 그런데, 차원을 단순히/무작정 작게만 만든다고 다 되는 것은 아니다. 적당한 크기가 필요하고, 그 다음의 레이어에서 학습할 만큼은 남겨둔 적당한 차원이어야한다. 이러한 구조를 잘 활용한 것이 bottleneck 이라는 구조이다.
bottleneck은 이름 그대로, >< 같은 모양이 되기 때문에 bottleneck 이다. 1x1 convolution으로 좁아졌다가, 3x3 convolution(원래 하고자 했던 연산)을 하고, 1x1 convolution으로 다시 차원의 깊이도 깊게만드는 block을 bottleneck 이라고 부른다. 실제로 하는 일은 비용이 많이 드는 3x3, 5x5 convolution을 하기 전에, 1x1 convolution을 하여 차원을 감소시킨 후에 3x3, 5x5 convolution을 수행하는 것이다. inception 모델에서 활용되어 파라미터의 수는 줄이고 레이어를 깊게 하였으며, 특히 ResNet에서 엄청난 효과를 나타내었다.
이게 주요 골자임. 또한 layer가 많아짐은 곧 활성화 함수가 기존보다 더 들어간다는 의미이고 이는 더 많은 non-linearity가 들어가게 되면서 Input을 다양하게 가공할 수 있음을 나타낸다.

(3, 1920, 1080)을 넣으면 각각 아래의 shape을 가짐.
----------------------------------------------------------------
Layer (type) Output Shape Param #
================================================================
Conv2d-1 [-1, 64, 960, 540] 9,408
BatchNorm2d-2 [-1, 64, 960, 540] 128
ReLU-3 [-1, 64, 960, 540] 0
MaxPool2d-4 [-1, 64, 480, 270] 0
Conv2d-5 [-1, 64, 480, 270] 4,096
BatchNorm2d-6 [-1, 64, 480, 270] 128
ReLU-7 [-1, 64, 480, 270] 0
Conv2d-8 [-1, 64, 480, 270] 36,864
BatchNorm2d-9 [-1, 64, 480, 270] 128
ReLU-10 [-1, 64, 480, 270] 0
Conv2d-11 [-1, 256, 480, 270] 16,384
BatchNorm2d-12 [-1, 256, 480, 270] 512
Conv2d-13 [-1, 256, 480, 270] 16,384
BatchNorm2d-14 [-1, 256, 480, 270] 512
ReLU-15 [-1, 256, 480, 270] 0
Bottleneck-16 [-1, 256, 480, 270] 0
Conv2d-17 [-1, 64, 480, 270] 16,384
BatchNorm2d-18 [-1, 64, 480, 270] 128
ReLU-19 [-1, 64, 480, 270] 0
Conv2d-20 [-1, 64, 480, 270] 36,864
BatchNorm2d-21 [-1, 64, 480, 270] 128
ReLU-22 [-1, 64, 480, 270] 0
Conv2d-23 [-1, 256, 480, 270] 16,384
BatchNorm2d-24 [-1, 256, 480, 270] 512
ReLU-25 [-1, 256, 480, 270] 0
Bottleneck-26 [-1, 256, 480, 270] 0
Conv2d-27 [-1, 64, 480, 270] 16,384
BatchNorm2d-28 [-1, 64, 480, 270] 128
ReLU-29 [-1, 64, 480, 270] 0
Conv2d-30 [-1, 64, 480, 270] 36,864
BatchNorm2d-31 [-1, 64, 480, 270] 128
ReLU-32 [-1, 64, 480, 270] 0
Conv2d-33 [-1, 256, 480, 270] 16,384
BatchNorm2d-34 [-1, 256, 480, 270] 512
ReLU-35 [-1, 256, 480, 270] 0
Bottleneck-36 [-1, 256, 480, 270] 0
Conv2d-37 [-1, 128, 480, 270] 32,768
BatchNorm2d-38 [-1, 128, 480, 270] 256
ReLU-39 [-1, 128, 480, 270] 0
Conv2d-40 [-1, 128, 240, 135] 147,456
BatchNorm2d-41 [-1, 128, 240, 135] 256
ReLU-42 [-1, 128, 240, 135] 0
Conv2d-43 [-1, 512, 240, 135] 65,536
BatchNorm2d-44 [-1, 512, 240, 135] 1,024
Conv2d-45 [-1, 512, 240, 135] 131,072
BatchNorm2d-46 [-1, 512, 240, 135] 1,024
ReLU-47 [-1, 512, 240, 135] 0
Bottleneck-48 [-1, 512, 240, 135] 0
Conv2d-49 [-1, 128, 240, 135] 65,536
BatchNorm2d-50 [-1, 128, 240, 135] 256
ReLU-51 [-1, 128, 240, 135] 0
Conv2d-52 [-1, 128, 240, 135] 147,456
BatchNorm2d-53 [-1, 128, 240, 135] 256
ReLU-54 [-1, 128, 240, 135] 0
Conv2d-55 [-1, 512, 240, 135] 65,536
BatchNorm2d-56 [-1, 512, 240, 135] 1,024
ReLU-57 [-1, 512, 240, 135] 0
Bottleneck-58 [-1, 512, 240, 135] 0
Conv2d-59 [-1, 128, 240, 135] 65,536
BatchNorm2d-60 [-1, 128, 240, 135] 256
ReLU-61 [-1, 128, 240, 135] 0
Conv2d-62 [-1, 128, 240, 135] 147,456
BatchNorm2d-63 [-1, 128, 240, 135] 256
ReLU-64 [-1, 128, 240, 135] 0
Conv2d-65 [-1, 512, 240, 135] 65,536
BatchNorm2d-66 [-1, 512, 240, 135] 1,024
ReLU-67 [-1, 512, 240, 135] 0
Bottleneck-68 [-1, 512, 240, 135] 0
Conv2d-69 [-1, 128, 240, 135] 65,536
BatchNorm2d-70 [-1, 128, 240, 135] 256
ReLU-71 [-1, 128, 240, 135] 0
Conv2d-72 [-1, 128, 240, 135] 147,456
BatchNorm2d-73 [-1, 128, 240, 135] 256
ReLU-74 [-1, 128, 240, 135] 0
Conv2d-75 [-1, 512, 240, 135] 65,536
BatchNorm2d-76 [-1, 512, 240, 135] 1,024
ReLU-77 [-1, 512, 240, 135] 0
Bottleneck-78 [-1, 512, 240, 135] 0
Conv2d-79 [-1, 256, 240, 135] 131,072
BatchNorm2d-80 [-1, 256, 240, 135] 512
ReLU-81 [-1, 256, 240, 135] 0
Conv2d-82 [-1, 256, 120, 68] 589,824
BatchNorm2d-83 [-1, 256, 120, 68] 512
ReLU-84 [-1, 256, 120, 68] 0
Conv2d-85 [-1, 1024, 120, 68] 262,144
BatchNorm2d-86 [-1, 1024, 120, 68] 2,048
Conv2d-87 [-1, 1024, 120, 68] 524,288
BatchNorm2d-88 [-1, 1024, 120, 68] 2,048
ReLU-89 [-1, 1024, 120, 68] 0
Bottleneck-90 [-1, 1024, 120, 68] 0
Conv2d-91 [-1, 256, 120, 68] 262,144
BatchNorm2d-92 [-1, 256, 120, 68] 512
ReLU-93 [-1, 256, 120, 68] 0
Conv2d-94 [-1, 256, 120, 68] 589,824
BatchNorm2d-95 [-1, 256, 120, 68] 512
ReLU-96 [-1, 256, 120, 68] 0
Conv2d-97 [-1, 1024, 120, 68] 262,144
BatchNorm2d-98 [-1, 1024, 120, 68] 2,048
ReLU-99 [-1, 1024, 120, 68] 0
Bottleneck-100 [-1, 1024, 120, 68] 0
Conv2d-101 [-1, 256, 120, 68] 262,144
BatchNorm2d-102 [-1, 256, 120, 68] 512
ReLU-103 [-1, 256, 120, 68] 0
Conv2d-104 [-1, 256, 120, 68] 589,824
BatchNorm2d-105 [-1, 256, 120, 68] 512
ReLU-106 [-1, 256, 120, 68] 0
Conv2d-107 [-1, 1024, 120, 68] 262,144
BatchNorm2d-108 [-1, 1024, 120, 68] 2,048
ReLU-109 [-1, 1024, 120, 68] 0
Bottleneck-110 [-1, 1024, 120, 68] 0
Conv2d-111 [-1, 256, 120, 68] 262,144
BatchNorm2d-112 [-1, 256, 120, 68] 512
ReLU-113 [-1, 256, 120, 68] 0
Conv2d-114 [-1, 256, 120, 68] 589,824
BatchNorm2d-115 [-1, 256, 120, 68] 512
ReLU-116 [-1, 256, 120, 68] 0
Conv2d-117 [-1, 1024, 120, 68] 262,144
BatchNorm2d-118 [-1, 1024, 120, 68] 2,048
ReLU-119 [-1, 1024, 120, 68] 0
Bottleneck-120 [-1, 1024, 120, 68] 0
Conv2d-121 [-1, 256, 120, 68] 262,144
BatchNorm2d-122 [-1, 256, 120, 68] 512
ReLU-123 [-1, 256, 120, 68] 0
Conv2d-124 [-1, 256, 120, 68] 589,824
BatchNorm2d-125 [-1, 256, 120, 68] 512
ReLU-126 [-1, 256, 120, 68] 0
Conv2d-127 [-1, 1024, 120, 68] 262,144
BatchNorm2d-128 [-1, 1024, 120, 68] 2,048
ReLU-129 [-1, 1024, 120, 68] 0
Bottleneck-130 [-1, 1024, 120, 68] 0
Conv2d-131 [-1, 256, 120, 68] 262,144
BatchNorm2d-132 [-1, 256, 120, 68] 512
ReLU-133 [-1, 256, 120, 68] 0
Conv2d-134 [-1, 256, 120, 68] 589,824
BatchNorm2d-135 [-1, 256, 120, 68] 512
ReLU-136 [-1, 256, 120, 68] 0
Conv2d-137 [-1, 1024, 120, 68] 262,144
BatchNorm2d-138 [-1, 1024, 120, 68] 2,048
ReLU-139 [-1, 1024, 120, 68] 0
Bottleneck-140 [-1, 1024, 120, 68] 0
Conv2d-141 [-1, 512, 120, 68] 524,288
BatchNorm2d-142 [-1, 512, 120, 68] 1,024
ReLU-143 [-1, 512, 120, 68] 0
Conv2d-144 [-1, 512, 60, 34] 2,359,296
BatchNorm2d-145 [-1, 512, 60, 34] 1,024
ReLU-146 [-1, 512, 60, 34] 0
Conv2d-147 [-1, 2048, 60, 34] 1,048,576
BatchNorm2d-148 [-1, 2048, 60, 34] 4,096
Conv2d-149 [-1, 2048, 60, 34] 2,097,152
BatchNorm2d-150 [-1, 2048, 60, 34] 4,096
ReLU-151 [-1, 2048, 60, 34] 0
Bottleneck-152 [-1, 2048, 60, 34] 0
Conv2d-153 [-1, 512, 60, 34] 1,048,576
BatchNorm2d-154 [-1, 512, 60, 34] 1,024
ReLU-155 [-1, 512, 60, 34] 0
Conv2d-156 [-1, 512, 60, 34] 2,359,296
BatchNorm2d-157 [-1, 512, 60, 34] 1,024
ReLU-158 [-1, 512, 60, 34] 0
Conv2d-159 [-1, 2048, 60, 34] 1,048,576
BatchNorm2d-160 [-1, 2048, 60, 34] 4,096
ReLU-161 [-1, 2048, 60, 34] 0
Bottleneck-162 [-1, 2048, 60, 34] 0
Conv2d-163 [-1, 512, 60, 34] 1,048,576
BatchNorm2d-164 [-1, 512, 60, 34] 1,024
ReLU-165 [-1, 512, 60, 34] 0
Conv2d-166 [-1, 512, 60, 34] 2,359,296
BatchNorm2d-167 [-1, 512, 60, 34] 1,024
ReLU-168 [-1, 512, 60, 34] 0
Conv2d-169 [-1, 2048, 60, 34] 1,048,576
BatchNorm2d-170 [-1, 2048, 60, 34] 4,096
ReLU-171 [-1, 2048, 60, 34] 0
Bottleneck-172 [-1, 2048, 60, 34] 0
AdaptiveAvgPool2d-173 [-1, 2048, 1, 1] 0
Linear-174 [-1, 1000] 2,049,000
================================================================
Total params: 25,557,032
Trainable params: 25,557,032
Non-trainable params: 0
----------------------------------------------------------------
Input size (MB): 23.73
Forward/backward pass size (MB): 11862.45
Params size (MB): 97.49
Estimated Total Size (MB): 11983.67
----------------------------------------------------------------이 때, Conv2d와 BatchNorm2d의 구조는
torch.nn.Conv2d(
in_channels,
out_channels,
kernel_size,
stride=1,
padding=0,
dilation=1,
groups=1,
bias=True,
padding_mode='zeros'
)또한
m = nn.BatchNorm2d("""채널 수""")
"""
num_features (int) – 인풋사이즈인(N, C, H, W)의 예상 C(채널) 수
eps(θ) – 수치 안정성을 위해 분모에 추가되는 값. 기본값: 1e-5
momentum(float) – running_messages 및 running_var 계산에 사용되는 값. 누적 이동 평균(즉, 단순 평균)에 대해 없음으로 설정할 수 있습니다. 기본값: 0.1
affine (boole) – True로 설정하면 이 모듈에 학습 가능한 affine 매개 변수가 있는 부울 값입니다. 기본값: T
track_running_stats (boole) – 이 모듈은 True로 설정하면 런닝 평균과 분산을 추적하고, False로 설정하면 해당 통계를 추적하지 않으며, running_mean 및 running_var 통계 버퍼를 없음으로 초기화하는 부울 값입니다. 이러한 버퍼가 없음이면 이 모듈은 항상 배치 통계를 사용합니다. 훈련 모드와 평가 모드 모두에서. 기본값: 진실의
"""def customRCNN을 보면
# default = T
if median_anchors:
anchor_sizes = cfg['anchor_sizes'] # 'anchor_sizes': ((12,), (32,), (64,), (112,), (196,), (256,), (384,), (512,))
aspect_ratios = cfg['aspect_ratios'] # 'aspect_ratios': ((0.5, 1.0, 1.5), (0.5, 1.0, 1.5), (0.5, 1.0, 1.5), (0.5, 1.0, 1.5), (0.5, 1.0, 1.5), (0.5, 1.0, 1.5), (0.5, 1.0, 1.5), (0.5, 1.0, 1.5))
"""
AnchorGenetor - https://tutorials.pytorch.kr/intermediate/torchvision_tutorial.html
이에 의하면, [12, 32, 64, ...]의 서로 다른 크기와 (0.5, 1.0, 1.5)의 다른 측면 비율(Aspect ratio)를 가진
8x3개의 앵커를 공간위치마다 생성하도록 한다고 한다.
이 aspect_ratio와 anchor_sizes에 관해서는 https://herbwood.tistory.com/10
"""
rpn_anchor_generator = AnchorGenerator(anchor_sizes,
aspect_ratios)
kwargs['rpn_anchor_generator'] = rpn_anchor_generator이라는 코드가 있음.
이 AnchorGenerator의 anchor_sizes와 aspect_ratios가 곧 하이퍼파라미터의 일종임.
Faster R-CNN 논문(Faster R-CNN: Towards Real-Time ObjectDetection with Region Proposal Networks) 리뷰
이번 포스팅에서는 Faster R-CNN 논문(Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks)을 읽고 정리해봤습니다. 기존 Fast R-CNN 모델은 여전히 Selective search 알고리즘을 통해 region proposals
herbwood.tistory.com
이는 여기에 잘 나와있음.
> /workspace/HeadHunter/head_detection/models/head_detect.py(130)customRCNN()->FasterRCNN(
...e)
)
)
)
-> return model
(Pdb) next
--Call--
> /usr/local/lib/python3.8/dist-packages/torch/nn/modules/module.py(444)cuda()
-> def cuda(self: T, device: Optional[Union[int, device]] = None) -> T:
(Pdb) next
> /usr/local/lib/python3.8/dist-packages/torch/nn/modules/module.py(458)cuda()
-> return self._apply(lambda t: t.cuda(device))head_detect.py의 return model을 진행하면, next는 바로 자신을 호출한 함수가 아니라, 의외로
torch.nn.modules.modules.py의 cuda()함수로 나아간다.
여기에서 def cuda - return self._apply(...)을 실행하고 바로 호출한 함수로 되돌아옴.
일단 혹시 모르니 적어둔다.
다음으로, 아직 지식이 짧아서 그런지 정확히 어느 단에서 image가 들어가서 작업을 하는 건지 이해가 되지 않기에,
import pdb
pdb.set_trace()
outputs = model(image)
>>> next(다음 줄로 이동)
>>> step(다음 실행 함수로 이동)을 일일이 찍어가며 한 번 확인해봤다. 그 결과,
> /workspace/HeadHunter/test.py(355)test()
-> outputs = model(images) # outputs : customRCNN에 images 넣은 결과. 즉 하나의 배치를 통째로 넣음.
--Call--
> /usr/local/lib/python3.8/dist-packages/torch/nn/modules/module.py(710)_call_impl()
-> def _call_impl(self, *input, **kwargs):
> /usr/local/lib/python3.8/dist-packages/torch/nn/modules/module.py(711)_call_impl()
-> for hook in itertools.chain(
> /usr/local/lib/python3.8/dist-packages/torch/nn/modules/module.py(712)_call_impl()
-> _global_forward_pre_hooks.values(),
> /usr/local/lib/python3.8/dist-packages/torch/nn/modules/module.py(713)_call_impl()
-> self._forward_pre_hooks.values()):
> /usr/local/lib/python3.8/dist-packages/torch/nn/modules/module.py(711)_call_impl()
-> for hook in itertools.chain(
> /usr/local/lib/python3.8/dist-packages/torch/nn/modules/module.py(719)_call_impl()
-> if torch._C._get_tracing_state():
> /usr/local/lib/python3.8/dist-packages/torch/nn/modules/module.py(722)_call_impl()
-> result = self.forward(*input, **kwargs)
--Call--
> /usr/local/lib/python3.8/dist-packages/torchvision/models/detection/generalized_rcnn.py(44)forward()
-> def forward(self, images, targets=None):
> /usr/local/lib/python3.8/dist-packages/torchvision/models/detection/generalized_rcnn.py(58)forward()
-> if self.training and targets is None:
> /usr/local/lib/python3.8/dist-packages/torchvision/models/detection/generalized_rcnn.py(60)forward()
-> if self.training:
> /usr/local/lib/python3.8/dist-packages/torchvision/models/detection/generalized_rcnn.py(73)forward()
-> original_image_sizes = torch.jit.annotate(List[Tuple[int, int]], [])
--Call--
> /usr/lib/python3.8/typing.py(802)__getitem__()
-> def __getitem__(self, params):
> /usr/lib/python3.8/typing.py(803)__getitem__()
-> if self._name != 'Callable' or not self._special:
> /usr/lib/python3.8/typing.py(804)__getitem__()
-> return self.__getitem_inner__(params)
--Call--
> /usr/lib/python3.8/typing.py(255)inner()
-> @functools.wraps(func)
> /usr/lib/python3.8/typing.py(257)inner()
-> try:
> /usr/lib/python3.8/typing.py(258)inner()
-> return cached(*args, **kwds)
--Call--
> /usr/lib/python3.8/typing.py(720)__hash__()
-> def __hash__(self):
> /usr/lib/python3.8/typing.py(721)__hash__()
-> if self.__origin__ is Union:
> /usr/lib/python3.8/typing.py(723)__hash__()
-> return hash((self.__origin__, self.__args__))
--Return--
> /usr/lib/python3.8/typing.py(723)__hash__()->-3768858926959439677
-> return hash((self.__origin__, self.__args__))
--Return--
> /usr/lib/python3.8/typing.py(258)inner()->typing.Tuple[int, int]
-> return cached(*args, **kwds)
--Return--
> /usr/lib/python3.8/typing.py(804)__getitem__()->typing.Tuple[int, int]
-> return self.__getitem_inner__(params)
--Call--
> /usr/lib/python3.8/typing.py(255)inner()
-> @functools.wraps(func)다음과 같은 결과를 획득.
즉, 우선은 바로 선언한 모델로 들어가는 것이 아닌, module.py의 _call_impl()라는 함수에 진입한다.
그 다음에 torchvision/models/detection/generalized_rcnn.py에 들어가는데, 이는 곧
fast_rcnn.py의 15줄에서 import하는 함수임.
또한 fast_rcnn.py의 FasterRCNN의 __init__함수 마지막단에
transform = GeneralizedRCNNTransform(image_mean, image_std, min_size, max_size)
super(FasterRCNN, self).__init__(backbone, rpn, roi_heads, transform)가 존재하고, 그 바로 아래에
class GeneralizedRCNNTransform(nn.Module):
def __init__(self, image_mean, image_std, min_size, max_size):
....가 존재하는 것을 볼 때, 실제로 이미지처리는 해당 클래스에서 진행하는 것을 알 수 있다.
즉, Generalized...는 (nn.Module)을 상속받고, FasterRCNN은 Generalized...를 상속받는다.
따라서 FasterRCNN에서 forward를 진행하면, Generalized...의 forward를 진행하게 된다.
실행순서를 살펴본 결과,
test.py에서 outputs = model(images)를 실행 시,
module.py - generalized_rcnn.py - typing.py - check_generic ... 등을 거쳐
비로소 head_detections/models/fast_rcnn.py 에 다다르게 되고,
여기에서 class GeneralizedRCNNTransform - forward()를 진행한 다음,
특이하게도 그 다음엔
models/net.py의 class_BackBoneWithFPN의 forward()에 다다르게 됨.
특이한 구조가 아닐 수 없다.
model = create_model(combined_cfg)
outputs = model(images)
def create_model : # test.py
model = customRCNN
return model
def customRCNN : # models/head_detect.py
backbone_with_fpn = create_backbone() = BackBoneWithFPN(nn.Module) # models/net.py
"""
class BackBoneWithFPN(nn.module) :
def __init__() :
def forward() :
"""
model = FasterRCNN(backbone_with_fpn)
return model
class FasterRCNN(GeneralizedRCNN) : # models/fast_rcnn.py
transform = GeneralizedRCNNTransform()
super(self, FasterRCNN).__init__(backbone)
class GeneralizedRCNN(nn.Module) : # models/fast_rcnn.py
def __init__():
super(GeneralizedRCNNTransform, self).__init__()
def forward(image): # 이미지는 여기에 들어가게 됨.구조는 위와 같다.
1행은 init을 실행하고, 2행은 forward를 실행한다는 것을 생각하면,
또한
> /workspace/HeadHunter/head_detection/models/fast_rcnn.py(180)forward()
-> return image_list, targets
(Pdb) step
--Return--
> /workspace/HeadHunter/head_detection/models/fast_rcnn.py(180)forward()->(<torchvision....x7fdf2857b8b0>, None)
-> return image_list, targets
(Pdb) step
...
--Call--
> /workspace/HeadHunter/head_detection/models/net.py(264)forward()
-> def forward(self, inputs):
(Pdb) step
> /workspace/HeadHunter/head_detection/models/net.py(265)forward()
-> feat_maps = self.body(inputs)로그는 위와 같다.
추측컨대, backbone으로 설치한 클래스의 forward가 자동으로 실행되는 것으로 보임.
이 backbone의 forward가 진정한 딥러닝 과정으로 보인다.
def forward(self, inputs):
feat_maps = self.body(inputs)
fpn_out = self.fpn(feat_maps)
fpn_out = list(fpn_out.values()) if isinstance(fpn_out, dict) else fpn_out
if self.context_list is not None:
context_out = [cont_i(fpn_f) for fpn_f, cont_i in zip(fpn_out, self.context_list)]
else:
context_out = fpn_out
# back to dict
feat_extracted = OrderedDict([(k, v) for k, v in zip(list(feat_maps.keys()), context_out)])
return feat_extracted의 첫 feat_maps = self.body(inputs)에 pdb.set_trace()를 찍어본 결과 batchnorm.py나 ReLU같은 게 실행 됨.
그리고 이후 fpn_out부터는 feature_pyramid_network.py 의 함수가 실행됨.
이후에 return feat_extracted를 한 다음에는
fast_rcnn.py의 def postprocess 실행.
> /usr/local/lib/python3.8/dist-packages/torchvision/models/detection/generalized_rcnn.py(100)forward()
-> detections = self.transform.postprocess(detections, images.image_sizes, original_image_sizes)
--Call--
> /usr/local/lib/python3.8/dist-packages/torch/nn/modules/module.py(758)__getattr__()
-> def __getattr__(self, name: str) -> Union[Tensor, 'Module']:
> /usr/local/lib/python3.8/dist-packages/torch/nn/modules/module.py(759)__getattr__()
-> if '_parameters' in self.__dict__:
> /usr/local/lib/python3.8/dist-packages/torch/nn/modules/module.py(760)__getattr__()
-> _parameters = self.__dict__['_parameters']
> /usr/local/lib/python3.8/dist-packages/torch/nn/modules/module.py(761)__getattr__()
-> if name in _parameters:
> /usr/local/lib/python3.8/dist-packages/torch/nn/modules/module.py(763)__getattr__()
-> if '_buffers' in self.__dict__:
> /usr/local/lib/python3.8/dist-packages/torch/nn/modules/module.py(764)__getattr__()
-> _buffers = self.__dict__['_buffers']
> /usr/local/lib/python3.8/dist-packages/torch/nn/modules/module.py(765)__getattr__()
-> if name in _buffers:
> /usr/local/lib/python3.8/dist-packages/torch/nn/modules/module.py(767)__getattr__()
-> if '_modules' in self.__dict__:
> /usr/local/lib/python3.8/dist-packages/torch/nn/modules/module.py(768)__getattr__()
-> modules = self.__dict__['_modules']
> /usr/local/lib/python3.8/dist-packages/torch/nn/modules/module.py(769)__getattr__()
-> if name in modules:
> /usr/local/lib/python3.8/dist-packages/torch/nn/modules/module.py(770)__getattr__()
-> return modules[name]
--Return--
> /usr/local/lib/python3.8/dist-packages/torch/nn/modules/module.py(770)__getattr__()->GeneralizedRCNNTransform()
-> return modules[name]
--Call--
> /workspace/HeadHunter/head_detection/models/fast_rcnn.py(235)postprocess()
-> def postprocess(self, result, image_shapes, original_image_sizes):이 postprocess는 /usr/local/lib/python3.8/dist-packages/torchvision/models/detection/generalized_rcnn.py(100)forward()처럼, 실제로 generalized_rcnn.py의 forward()함수로 인해 실행된 것을 보임.
> /usr/local/lib/python3.8/dist-packages/torch/nn/modules/module.py(744)_call_impl()->([{'boxes': tensor([[1340...vice='cuda:0'), 'labels': tensor([1], device='cuda:0'), 'scores': tensor([0.869...vice='cuda:0')}], {})
-> return result
> /usr/local/lib/python3.8/dist-packages/torchvision/models/detection/generalized_rcnn.py(100)forward()
-> detections = self.transform.postprocess(detections, images.image_sizes, original_image_sizes)
--Call--
> /usr/local/lib/python3.8/dist-packages/torch/nn/modules/module.py(758)__getattr__()
-> def __getattr__(self, name: str) -> Union[Tensor, 'Module']:
> /usr/local/lib/python3.8/dist-packages/torch/nn/modules/module.py(759)__getattr__()
-> if '_parameters' in self.__dict__:
> /usr/local/lib/python3.8/dist-packages/torch/nn/modules/module.py(760)__getattr__()
-> _parameters = self.__dict__['_parameters']
> /usr/local/lib/python3.8/dist-packages/torch/nn/modules/module.py(761)__getattr__()
-> if name in _parameters:
> /usr/local/lib/python3.8/dist-packages/torch/nn/modules/module.py(763)__getattr__()
-> if '_buffers' in self.__dict__:
> /usr/local/lib/python3.8/dist-packages/torch/nn/modules/module.py(764)__getattr__()
-> _buffers = self.__dict__['_buffers']
> /usr/local/lib/python3.8/dist-packages/torch/nn/modules/module.py(765)__getattr__()
-> if name in _buffers:
> /usr/local/lib/python3.8/dist-packages/torch/nn/modules/module.py(767)__getattr__()
-> if '_modules' in self.__dict__:
> /usr/local/lib/python3.8/dist-packages/torch/nn/modules/module.py(768)__getattr__()
-> modules = self.__dict__['_modules']
> /usr/local/lib/python3.8/dist-packages/torch/nn/modules/module.py(769)__getattr__()
-> if name in modules:
> /usr/local/lib/python3.8/dist-packages/torch/nn/modules/module.py(770)__getattr__()
-> return modules[name]
--Return--
> /usr/local/lib/python3.8/dist-packages/torch/nn/modules/module.py(770)__getattr__()->GeneralizedRCNNTransform()
-> return modules[name]이 fast_rcnn.py - postprocess가 마치고 나서야 outputs = model(images)가 끝나고 다음 줄로 넘어가게 됨.
'블루아카이브' 카테고리의 다른 글
| PCA (0) | 2023.12.12 |
|---|---|
| Forward-Forward 이해용 (0) | 2023.01.20 |
| BERT & RoBERTa & CORD & NER (0) | 2022.12.17 |
| 에러 기록 (0) | 2022.11.18 |
| Visual Transformer (0) | 2022.08.22 |



