참조글 - https://say-young.tistory.com/entry/CS231n-Lecture-7-Regularization?category=923651
CS231n - Lecture 7 (Regularization)
CS231n Lecture7 - Training Neural NetworksⅡ의 후반부를 듣고, 동아리 세미나 수강 후 정리한 내용입니다. 오류를 발견하시면 댓글로 말씀해주세요. CS231n Convolutional Neural Networks for Visual Recognit..
say-young.tistory.com
Optimization은, 학습을 어떻게 효율적으로 진행할 것인가(local minima에 빠지지 않게 하기, 학습의 step을 최적화하기 등등.... 말그대로 optimize하는 것)이었다면,
Regularization은 그 학습된 걸 어떻게 광범위하게 적용될수 있도록 하는가에 대한 것이다(이를테면 dropout 등... 과적합 피하게 하는 것)

1) 앙상블 : 여러 개의 모델을 학습시키고, 그 결과들을 평균을 내서 사용하기.
매번 여러 개의 모델을 학습시키는 것은 시간/비용적 부담이 있기에, 학습 중간 중간에 여러 번 저장을 해서(그림에는 깃발로 표시되어 있다.) 그것을 각각의 모델처럼 취급하기도 한다.
혹은 하단 그래프처럼 여러 개의 learning rate를 사용해서 여러 지점에 수렴하도록 할 수도 있다.

2) Drop-out : Forward pass 과정에서 일부 뉴런들의 activation 값을 랜덤하게 0으로 만들어버리는 방식.
이때 얼마나 drop할지는 hyperparameter로 우리가 직접 정해주게 되는데, 보통은 0.5로 설정한다(50%의 뉴런을 0으로).
왜 이것이 효과적인가? 하나의 노드를 '하나의 feature에 대한 1명의 전문가'라고 하면, 하나의 벡터에 대해 너무 많은 전문가들이 있는 것은 성능 향상에 큰 도움이 되지 않기 때문에, 오히려 이런 전문가들의 수를 줄여서 feature가 co-adaptation 되는 것을 막아준다는 의미다. 이때 전문가의 능력이 떨어지는 것이 아니고, 하나의 feature에 대해서 과하게 많은 전문가가 있는 상황을 막아주는 방식이 dropout이라 한다...
co-adaptation : 어떤 뉴런이 다른 특정 뉴런에 의존적으로 변하는 것
상호적응 문제는, 신경망의 학습 중 어느 시점에서 같은 층의 두 개 이상의 노드의 입력 및 출력 연결 강도가 같아지면, 아무리 학습이 진행되어도 그 노드들은 같은 일을 수행하게 되어 불필요한 중복이 생기는 문제를 말한다. 즉 연결 강도들이 학습을 통해 업데이트 되더라도 이들은 계속해서 서로 같은 입출력 연결 강도들을 유지하게 되고 이는 결국 하나의 노드로 작동하는 것으로써, 이후 어떠한 학습을 통해서도 이들은 다른 값으로 나눠질 수 없고 상호 적응하는 노드들에는 낭비가 발생하는 것이다. 결국 이것은 컴퓨팅 파워와 메모리의 낭비로 이어진다.
요약하자면.. 두 개 이상의 노드가 같은 일을 수행하게 되어서 불필요한 중복이 생긴다. 낭비다!! 라는 뜻으로 이해했다. 이렇게 중복으로 인한 낭비가 발생하기 때문에 dropout을 통해서 문제를 해결하는 것이었다.

노드 하나를 하나의 모델로 생각하면, dropout 방식은 앞서 말했던 모델 앙상블의 일종으로도 이해할 수 있다고 한다. 하나의 모델에서 랜덤한 dropout을 통해서 랜덤한 서브 네트워크가 형성되면서 앙상블의 효과를 낼 수 있기 때문이다.
위 그림의 오른쪽 그림처럼, 왼쪽의 베이스 네트워크를 여러 가지 방식으로 dropout 하면서 변조를 줌으로써, 다양한 서브 네트워크가 생기게 되고, 이러한 것들이 앙상블의 효과를 내면서 overfitting을 감소시킬 수 있게 되는 것이다.

수식. 아웃풋을 계산할 때, 추가적으로 랜덤한 마스크 z가 추가된다. 이를 통해 랜덤한 아웃풋이 도출되는데, 이 때 매번 랜덤한 모델로 결과를 도출하면 안 되기에, 이렇게 부여된 랜덤니스를 average-out할 방법이 필요하다고 한다.

3 ) 이전에도 언급한 바 있는 배치 정규화로, 각 층에서의 활성화 값을 적당히 분포시킴으로써, 학습의 속도 증가, 초기값 의존성 감소, 오버피팅 억제 담당자. mini batch를 활용해, 하나의 데이터를 매번 다른 데이터들과 조합해서 랜덤성을 부여. 이전과 마찬가지로, 테스트를 할 때는 매번 랜덤하게 결과를 도출하면 안 되기 때문에, 테스트를 할 때는 mini batch를 사용하지 않고 글로벌하게 수행을 해서 이때 생긴 randomness를 average-out 시켜준다.

4) Data augmentation : 패스.
Random erasing이라고, 사진의 일부를 일부려 가려버리는 경우도 있다 한다.

5) Drop Connection : DropOut과는 달리, activation(ReLU, Sigmoid등의 출력값)을 0으로 바꾸는게 아니라, 가중치를 0으로 만들어버린다.
어쨌든 ReLU나 Sigmoid는 0이 들어올 때의 출력값이 있으니 그게 나오겠지?

6) Fractional Max Pooling :
말 그대로 풀링 영역을 랜덤으로. 예시 이미지를 보면 알 수 있듯, 그냥 보면 이미지에 Aliasing이 일어날 것처럼 생겼다.
이 방법을 통해 랜덤성이 부여가 되는데 테스트를 할 때는 고정된 pooling 영역을 사용해서 이 랜덤성을 average-out

7) stochastic depth : 왼쪽 그림이 training 할 때의 그림이고, 오른쪽이 test 할 때의 그림.
training을 할 때는 왼쪽처럼 네트워크의 depth를 랜덤하게 drop해주고, test를 할 때는 drop하지 않고 전체 네트워크를 사용한다. 이 방식은 dropout과 유사한 효과를 낸다.
위 방법의 공통점은,
- training을 할 때는 랜덤한 noise를 줌으로써 randomness를 더해주고
- test를 할 때는 이러한 randomness를 average-out 시켜주면서 일관성 있는 결과를 낼 수 있도록 한다.

transfer learning : 사전에 미리 학습된 모델을 사용. 절차는 아래와 같다.
(1) 큰 데이터 셋으로 먼저 학습을 시켜준다.
(2) 사용하고자 하는 데이터 셋이 굉장히 작을 경우, 아래 레이어들은 전부 얼려주고(freeze), 마지막 부분의 레이어만 다시 초기화하고 학습해서 우리가 원하는 데이터 셋을 적용시켜준다.
(3) 데이터 셋이 클 경우에는 좀 더 많은 레이어들을 직접 학습해도 좋은 결과를 낼 수 있다.

CNN에서의 전이학습을 좀 더 자세히 살펴보자.
CNN 중 image classification 모델의 구조를 살펴보면 크게 convolutional base와 classifier로 이루어져 있다.
convolutional base - 이미지에서 특징을 추출하는 부분
classifier - convolutional base에서 추출된 특징을 입력받아, 이미지의 카테고리를 결정하는 classification을 진행.
| Quadrant 1 가진 데이터가 크고 기존에 학습된 데이터와 많이 다를 경우 큰 데이터를 가지고 있기 때문에 그냥 전체 모델을 다시 학습시켜주는 것이 좋은 선택일 수 있다. |
Quadrant 2 가진 데이터가 크고 기존과 유사한 경우 일반적으로 가장 좋은 경우다! 몇몇 레이어들만 적당히 freeze 시키고 나머지를 학습시켜줄 수 있다. |
| Quadrant 3 가진 데이터가 작은데 기존과도 다를 경우 일반적으로 가장 어려운 경우. 여러 가지 방법을 시도해보면서 일부 레이어들을 학습시키는 방향으로 진행하는 것이 좋다고 한다. |
Quadrant 4 가진 데이터가 작고 기존과 유사할 경우 convolutional base는 그대로 얼려두고 마지막 classifier 부분에서만 새로운 데이터로 학습을 시켜주면 좋은 결과를 얻을 수 있을 것이다. |
그래서 이런 전이 학습을 사용한다면 높은 정확도를 얻을 수 있고 시간 단축도 가능하기 때문에 굉장히 많이 사용된다. 다음은 이러한 전이 학습에 많이 사용되는 여러 네트워크들이다.
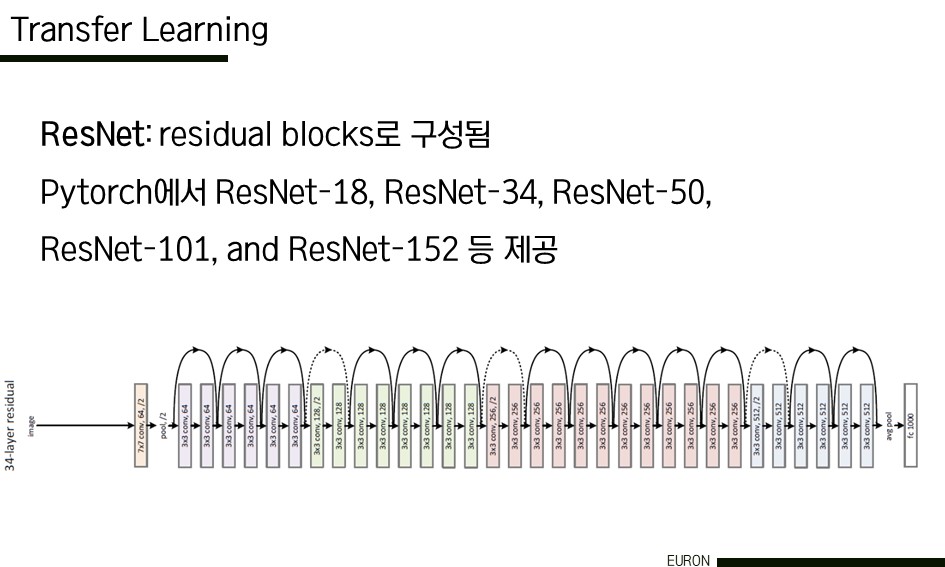

먼저 왼쪽은 ResNet이다. residual block들로 구성이 되어 있고 pytorch에서 기본적으로 여러 레이어들을 갖는 resnet 모델이 제공이 된다. 오른쪽은 VGG이다. 이 역시 n개의 층을 가진 vgg-11, vgg-13 등등 다양한 모델이 학습된 상태로 pytorch에서 제공이 되고 있다. 이외에도 GoogLeNet, AlexNet, SqueezeNet, DenseNet, ShuffleNetv2 등등 다양한 모델을 활용할 수 있다. 지금은 모두에게 공개되어 있는 큰 데이터 셋이 많기 때문에, transfer learning을 통해서 여러 가지를 시도해볼 수 있을 것이다.
전체적으로 수학적 기법이라기 보단 "이런게 있습니다~"라는 영역이라 그런갑다~ 하고 넘어간다.
'버츄얼유튜버' 카테고리의 다른 글
| RNN & LSTM (0) | 2022.07.30 |
|---|---|
| 여러 CNN 아키텍처(LeNet, GoogleNet, Alexnet, VGG, ResNet) (0) | 2022.07.28 |
| 메지로라이언이 시원시원하게 푸는 역전파&활성화, Optimizer (0) | 2022.07.21 |
| 통계 잡다 (0) | 2022.07.20 |
| 이미지분류 위한 공부 (0) | 2022.04.08 |


